Ajustez finement Falcon 7B et d’autres LLMs sur Amazon SageMaker avec le décorateur @remote
Ajustez finement Falcon 7B et d'autres LLMs sur Amazon SageMaker avec @remote
Aujourd’hui, les modèles d’IA générative couvrent une variété de tâches allant de la synthèse de texte, aux questions-réponses, en passant par la génération d’images et de vidéos. Pour améliorer la qualité des résultats, des approches telles que l’apprentissage à n-échantillons, l’ingénierie de prompt, la génération augmentée par récupération (RAG) et le fine-tuning sont utilisées. Le fine-tuning vous permet d’ajuster ces modèles d’IA générative pour obtenir de meilleures performances sur vos tâches spécifiques à un domaine.
Avec Amazon SageMaker, vous pouvez maintenant exécuter une tâche de formation de SageMaker simplement en annotant votre code Python avec le décorateur @remote. Le kit de développement logiciel Python de SageMaker traduit automatiquement votre environnement de travail existant, ainsi que tout le code de traitement des données associé et les ensembles de données, en une tâche de formation SageMaker qui s’exécute sur la plateforme de formation. Cela présente l’avantage d’écrire le code de manière plus naturelle et orientée objet, tout en utilisant les capacités de SageMaker pour exécuter les tâches de formation sur un cluster distant avec des modifications minimales.
Dans cet article, nous présentons comment effectuer un fine-tuning d’un modèle Foundation Models (FM) Falcon-7B en utilisant le décorateur @remote du kit de développement logiciel Python de SageMaker. Il utilise également la bibliothèque de fine-tuning (PEFT) à efficacité paramétrique de Hugging Face et des techniques de quantification à l’aide de bitsandbytes pour prendre en charge le fine-tuning. Le code présenté dans ce blog peut également être utilisé pour effectuer un fine-tuning d’autres FMs, tels que Llama-2 13b.
Les représentations en pleine précision de ce modèle peuvent présenter des difficultés pour tenir en mémoire sur une ou même plusieurs unités de traitement graphique (GPU) – ou peuvent même nécessiter une instance plus grande. Par conséquent, afin d’effectuer un fine-tuning de ce modèle sans augmenter les coûts, nous utilisons la technique connue sous le nom d’Adaptateurs Quantifiés LLMs avec Faible Rang (QLoRA). QLoRA est une approche de fine-tuning efficace qui réduit l’utilisation de la mémoire des LLMs tout en maintenant de très bonnes performances.
- Créez un pipeline de classification avec la classification personnalisée d’Amazon Comprehend (Partie I)
- Crier sur le Diable ‘Devil May Cry 5’ de Capcom rejoint GeForce NOW
- Étude explique le rôle de certains types d’oxyde dans la structure et le développement du verre spécialisé
@remote decorator
Avant d’aller plus loin, comprenons comment le décorateur @remote améliore la productivité des développeurs lorsqu’ils travaillent avec SageMaker :
- Le décorateur @remote déclenche directement une tâche de formation en utilisant du code Python natif, sans l’invocation explicite des estimateurs SageMaker et des canaux d’entrée SageMaker.
- Une faible barrière à l’entrée pour les développeurs qui effectuent la formation de modèles sur SageMaker.
- Pas besoin de changer d’environnement de développement intégré (EDI). Continuez à écrire du code dans l’EDI de votre choix et invoquez des tâches de formation SageMaker.
- Il n’est pas nécessaire d’apprendre à utiliser des conteneurs. Continuez à fournir les dépendances dans un fichier
requirements.txtet fournissez-le au décorateur @remote.
Prérequis
Un compte AWS est nécessaire avec un rôle AWS Identity and Access Management (IAM) ayant les autorisations nécessaires pour gérer les ressources créées dans le cadre de la solution. Pour plus de détails, consultez la création d’un compte AWS.
Dans cet article, nous utilisons Amazon SageMaker Studio avec l’image Data Science 3.0 et une instance de lancement rapide ml.t3.medium. Cependant, vous pouvez utiliser n’importe quel environnement de développement intégré (EDI) de votre choix. Il vous suffit de configurer correctement vos informations d’identification de l’interface de ligne de commande AWS (AWS CLI). Pour plus d’informations, consultez la configuration de l’interface de ligne de commande AWS.
Pour le fine-tuning, nous utilisons le modèle Falcon-7B sur une instance ml.g5.12xlarge dans cet article. Assurez-vous d’avoir suffisamment de capacité pour cette instance dans votre compte AWS.
Vous devez cloner ce dépôt Github pour reproduire la solution présentée dans cet article.
Aperçu de la solution
- Installer les pré-requis pour le fine-tuning du modèle Falcon-7B
- Configurer les paramètres du décorateur @remote
- Prétraiter l’ensemble de données contenant les FAQ sur les services AWS
- Fine-tune Falcon-7B sur les FAQ des services AWS
- Tester les modèles fine-tunés sur des questions d’échantillon liées aux services AWS
1. Installer les pré-requis pour le fine-tuning du modèle Falcon-7B
Ouvrez le notebook falcon-7b-qlora-remote-decorator_qa.ipynb dans SageMaker Studio en sélectionnant l’image Data Science et le Kernel Python 3. Installez toutes les bibliothèques requises mentionnées dans le fichier requirements.txt. Certaines des bibliothèques doivent être installées sur l’instance du notebook elle-même. Effectuez les autres opérations nécessaires pour le traitement de l’ensemble de données et le déclenchement d’une tâche de formation SageMaker.
%pip install -r requirements.txt
%pip install -q -U transformers==4.31.0
%pip install -q -U datasets==2.13.1
%pip install -q -U peft==0.4.0
%pip install -q -U accelerate==0.21.0
%pip install -q -U bitsandbytes==0.40.2
%pip install -q -U boto3
%pip install -q -U sagemaker==2.154.0
%pip install -q -U scikit-learn2. Configuration des paramètres du décorateur à distance
Créez un fichier de configuration où sont spécifiées toutes les configurations liées au travail de formation d’Amazon SageMaker. Ce fichier est lu par le décorateur @remote lors de l’exécution du travail de formation. Ce fichier contient des paramètres tels que les dépendances, l’image de formation, l’instance et le rôle d’exécution à utiliser pour le travail de formation. Pour une référence détaillée de tous les paramètres pris en charge par le fichier de configuration, consultez “Configuration et utilisation des valeurs par défaut avec le kit de développement logiciel Python SageMaker”.
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: ./requirements.txt
ImageUri: '{aws_account_id}.dkr.ecr.{region}.amazonaws.com/huggingface-pytorch-training:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04'
InstanceType: ml.g5.12xlarge
RoleArn: arn:aws:iam::111122223333:role/ExampleSageMakerRoleIl n’est pas obligatoire d’utiliser le fichier config.yaml pour travailler avec le décorateur @remote. C’est juste une façon plus propre de fournir toutes les configurations au décorateur @remote. Cela permet de garder les paramètres liés à SageMaker et AWS en dehors du code avec un effort unique pour configurer le fichier de configuration utilisé par les membres de l’équipe. Toutes les configurations peuvent également être fournies directement dans les arguments du décorateur, mais cela réduit la lisibilité et la maintenabilité des modifications à long terme. De plus, le fichier de configuration peut être créé par un administrateur et partagé avec tous les utilisateurs dans un environnement.
Prétraitement de l’ensemble de données contenant les FAQ des services AWS
La prochaine étape consiste à charger et prétraiter l’ensemble de données pour le préparer à la tâche de formation. Tout d’abord, examinons l’ensemble de données :
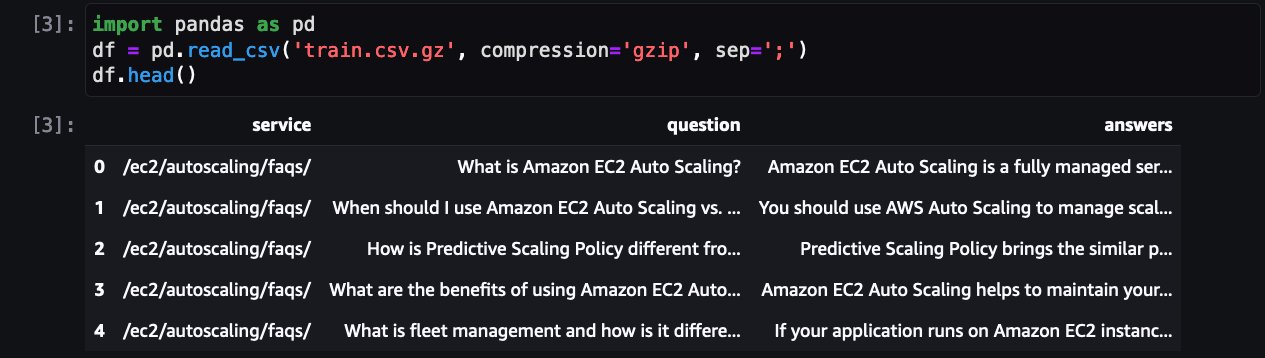
Cela montre une FAQ pour l’un des services AWS. En plus de QLoRA, bitsanbytes est utilisé pour convertir en précision sur 4 bits pour quantifier LLM gelé sur 4 bits et attacher des adaptateurs LoRA dessus.
Créez un modèle de prompt pour convertir chaque exemple de FAQ en un format de prompt :
from random import randint
# Début de l'instruction personnalisée du prompt
prompt_template = f"{{question}}\n---\nAnswer:\n{{answer}}{{eos_token}}"
# Ensemble de données modèle pour ajouter le prompt à chaque échantillon
def template_dataset(sample):
sample["text"] = prompt_template.format(question=sample["question"],
answer=sample["answers"],
eos_token=tokenizer.eos_token)
return sampleLa prochaine étape consiste à convertir les entrées (texte) en identifiants de jetons. Cela est fait par un tokenizer Hugging Face Transformers.
from transformers import AutoTokenizer
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Définir le tokenizer Falcon
tokenizer.pad_token = tokenizer.eos_tokenIl suffit maintenant d’utiliser la fonction prompt_template pour convertir toutes les FAQ en format de prompt et configurer les ensembles de données d’entraînement et de test.

4. Réglage fin de Falcon-7B sur les FAQ des services AWS
Maintenant, vous pouvez préparer le script de formation et définir la fonction de formation train_fn et placer le décorateur @remote sur la fonction.
La fonction de formation fait ce qui suit :
- tokenize et découpe l’ensemble de données
- configure
BitsAndBytesConfig, qui spécifie que le modèle doit être chargé sur 4 bits mais que le calcul doit être converti enbfloat16. - Charge le modèle
- Trouve les modules cibles et met à jour les matrices nécessaires en utilisant la méthode utilitaire
find_all_linear_names - Crée des configurations LoRA qui spécifient le classement des matrices de mise à jour (
s), le facteur d’échelle (lora_alpha), les modules pour appliquer les matrices de mise à jour LoRA (target_modules), la probabilité de désactivation pour les couches Lora (lora_dropout),task_type, etc. - Démarre la formation et l’évaluation
import bitsandbytes as bnb
def find_all_linear_names(hf_model):
lora_module_names = set()
for name, module in hf_model.named_modules():
if isinstance(module, bnb.nn.Linear4bit):
names = name.split(“.”)
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if “lm_head” in lora_module_names:
lora_module_names.remove(“lm_head”)
return list(lora_module_names)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from sagemaker.remote_function import remote
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
import transformers
# Commencer l’entraînement
@remote(volume_size=50)
def train_fn(
model_name,
train_ds,
test_ds,
lora_r=8,
lora_alpha=32,
lora_dropout=0.05,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
learning_rate=2e-4,
num_train_epochs=1
):
# Tokeniser et découper l’ensemble de données
lm_train_dataset = train_ds.map(
lambda sample: tokenizer(sample[“text”]), batched=True, batch_size=24, remove_columns=list(train_dataset.features)
)
lm_test_dataset = test_ds.map(
lambda sample: tokenizer(sample[“text”]), batched=True, remove_columns=list(test_dataset.features)
)
# Afficher le nombre total d’échantillons
print(f”Nombre total d’échantillons d’entraînement: {len(lm_train_dataset)}”)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type=”nf4″,
bnb_4bit_compute_dtype=torch.bfloat16
)
# Falcon exige d’autoriser l’exécution de code à distance. Cela est dû au fait que le modèle utilise une nouvelle architecture qui ne fait pas encore partie de transformers.
# Le code est fourni par les auteurs du modèle dans le dépôt.
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
quantization_config=bnb_config,
device_map=”auto”)
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
# Obtenir les modules cibles Lora
modules = find_all_linear_names(model)
print(f”Trouvé {len(modules)} modules à quantifier: {modules}”)
config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=modules,
lora_dropout=lora_dropout,
bias=”none”,
task_type=”CAUSAL_LM”
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
trainer = transformers.Trainer(
model=model,
train_dataset=lm_train_dataset,
eval_dataset=lm_test_dataset,
args=transformers.TrainingArguments(
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
logging_steps=2,
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
bf16=True,
save_strategy=”no”,
output_dir=”outputs”
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()
trainer.evaluate()
model.save_pretrained(“/opt/ml/model”)
Et invoquer train_fn()
train_fn(identifiant_modèle, ensemble_données_entrainement, ensemble_données_test)Le job de tuning s’exécutera sur le cluster d’entraînement d’Amazon SageMaker. Attendez que le job de tuning se termine.
5. Tester les modèles de fine-tuning sur des questions d’échantillon relatives aux services AWS
Maintenant, il est temps d’exécuter quelques tests sur le modèle. Tout d’abord, chargeons le modèle :
from peft import PeftModel, PeftConfig
import torch
from transformers import AutoModelForCausalLM
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
config = PeftConfig.from_pretrained("./model")
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, trust_remote_code=True)
model = PeftModel.from_pretrained(model, "./model")
model.to(device)Ensuite, chargeons une question d’échantillon provenant de l’ensemble de données d’entraînement pour voir la réponse originale, puis posons la même question au modèle ajusté pour comparer les réponses.
Voici un exemple de question provenant de l’ensemble d’entraînement et de la réponse originale :
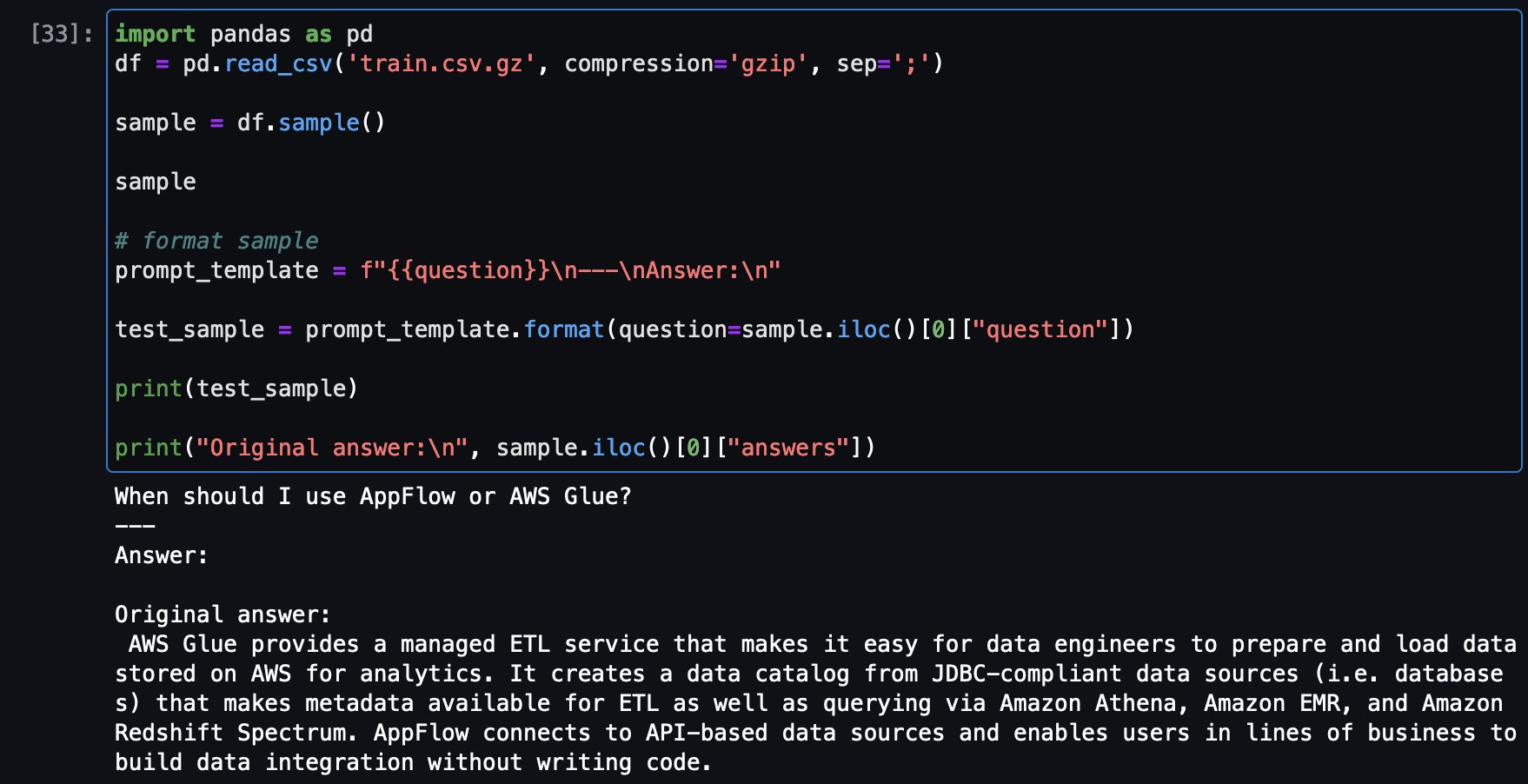
Maintenant, la même question est posée au modèle Falcon-7B ajusté :
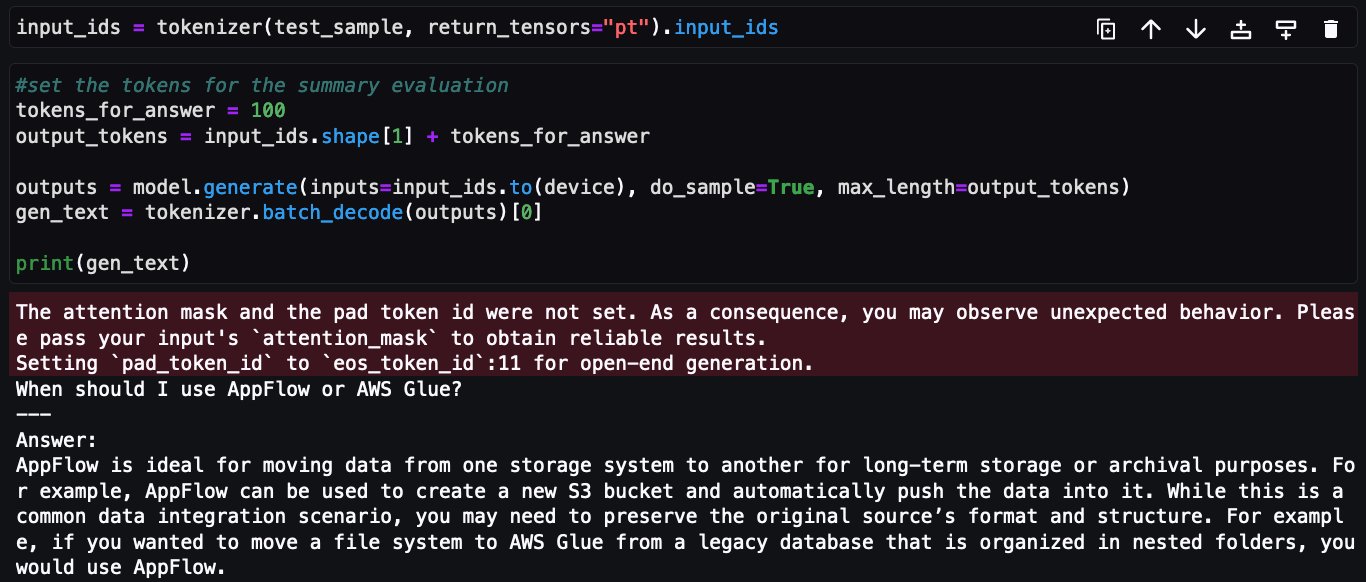
Cela conclut la mise en œuvre de l’ajustement fin du modèle Falcon-7B sur l’ensemble de données de FAQ des services AWS en utilisant le décorateur @remote du kit de développement Python Amazon SageMaker.
Nettoyage
Effectuez les étapes suivantes pour nettoyer vos ressources :
-
Arrêtez les instances d’Amazon SageMaker Studio pour éviter des coûts supplémentaires.
-
Nettoyez le répertoire du système de fichiers élastique Amazon (Amazon EFS) en effaçant le répertoire de cache Hugging Face :
rm -R ~/.cache/huggingface/hub
Conclusion
Dans ce billet, nous vous avons montré comment utiliser efficacement les capacités du décorateur @remote pour ajuster finement le modèle Falcon-7B en utilisant QLoRA, Hugging Face PEFT avec bitsandbytes sans apporter de modifications significatives au notebook d’entraînement, et nous avons utilisé les capacités d’Amazon SageMaker pour exécuter des tâches d’entraînement sur un cluster distant.
Tout le code présenté dans ce billet pour affiner le modèle Falcon-7B est disponible dans le référentiel GitHub. Le référentiel contient également un notebook montrant comment affiner le modèle Llama-13B.
Comme prochaine étape, nous vous encourageons à découvrir les fonctionnalités du décorateur @remote et de l’API Python SDK et à les utiliser dans l’environnement et l’IDE de votre choix. Des exemples supplémentaires sont disponibles dans le référentiel amazon-sagemaker-examples pour vous permettre de démarrer rapidement. Vous pouvez également consulter les billets suivants :
- Exécutez votre code d’apprentissage automatique local en tant que tâches d’entraînement Amazon SageMaker avec un minimum de modifications de code
- Accédez aux dépôts privés en utilisant le décorateur @remote pour les charges de travail d’entraînement Amazon SageMaker
- Affinez de manière interactive le modèle Falcon-40B et d’autres LLM sur les notebooks Amazon SageMaker Studio en utilisant QLoRA
We will continue to update IPGirl; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aider à la compréhension de l’informatique visuelle et des modèles de langage de ce qu’ils voient
- Le capital-investissement recrute des talents en science des données alors que l’industrie s’attaque à l’apprentissage automatique
- Segmenter n’importe quoi segmentation configurable d’objets arbitraires
- Comment l’apprentissage automatique peut être utilisé pour réduire les factures d’énergie
- Poursuivez un master en science des données avec le 3ème meilleur programme en ligne
- Data Science vs Ingénieur Logiciel Quelle est la meilleure carrière?
- Série de Fibonacci en Python | Code, Algorithme et Plus





