Régression CatBoost Expliquez-le moi en détail
Expliquez-moi en détail la Régression CatBoost
Une analyse complète (et illustrée) du fonctionnement interne de CatBoost
CatBoost, abréviation de Categorical Boosting, est un puissant algorithme d’apprentissage automatique qui excelle dans le traitement des caractéristiques catégorielles et la production de prédictions précises. Traditionnellement, la manipulation de données catégorielles est assez délicate, nécessitant un encodage one-hot, un encodage par étiquette ou une autre technique de prétraitement pouvant distordre la structure inhérente des données. Pour résoudre ce problème, CatBoost utilise son propre système d’encodage intégré appelé Ordered Target Encoding.
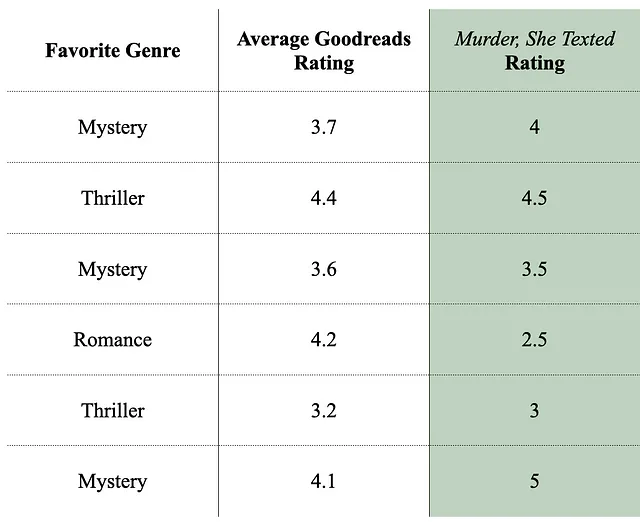
Voyons comment CatBoost fonctionne en pratique en construisant un modèle pour prédire comment quelqu’un pourrait évaluer le livre “Murder, She Texted” en fonction de leur note moyenne des livres sur Goodreads et de leur genre préféré.
Nous avons demandé à 6 personnes d’évaluer “Murder, She Texted” et avons collecté les autres informations pertinentes à leur sujet.
- L’implémentation du momentum de Nesterov de PyTorch est-elle incorrecte ?
- Débloquer le pouvoir de la diversité dans les réseaux neuronaux comment les neurones adaptatifs surpassent l’homogénéité dans la classification d’images et la régression non linéaire
- Au-delà de la courbe de Gauss Une introduction à la distribution de t
Voici notre ensemble de données d’entraînement actuel, que nous utiliserons pour entraîner les données (évidemment).
Étape 1 : Mélanger l’ensemble de données et Encoder les Données Catégorielles en Utilisant l’Encodage Ciblé Ordonné
La façon dont nous prétraitons les données catégorielles est essentielle à l’algorithme CatBoost. Dans ce cas, nous n’avons qu’une seule colonne catégorielle – Genre préféré. Cette colonne est encodée (c’est-à-dire convertie en un entier discret) et la manière dont cela est fait varie en fonction du problème de régression ou de classification. Étant donné que nous traitons un problème de régression (car la variable que nous voulons prédire, la note de “Murder, She Texted”, est continue), nous suivons les étapes suivantes.
1 – Mélanger l’ensemble de données :
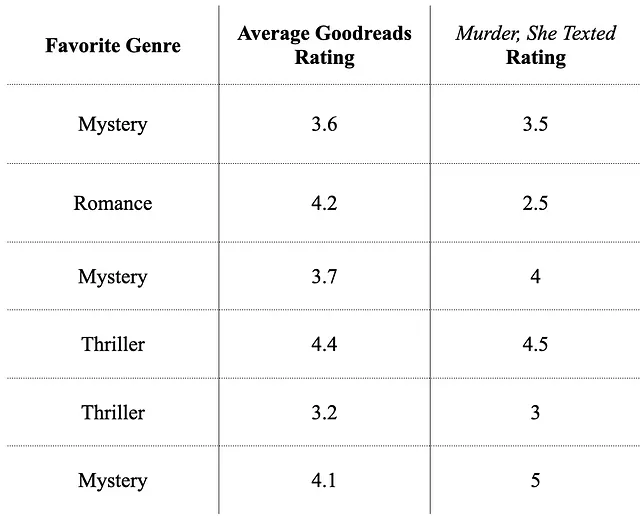
2 – Placer la variable cible continue dans des intervalles discrets : Comme nous avons très peu de données ici, nous allons créer 2 intervalles de même taille pour catégoriser la cible. (En savoir plus sur la création d’intervalles ici).
Nous plaçons les 3 plus petites valeurs de la note de “Murder, She Texted” dans l’intervalle 0 et le reste dans l’intervalle 1.
We will continue to update IPGirl; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Suivi des modèles d’apprentissage automatique en production pourquoi et comment ?
- Le problème de perception publique de l’apprentissage automatique
- Comprendre en profondeur les scores AUC quel est l’intérêt ?
- Le Guide Ultime pour Former BERT à partir de Zéro Introduction
- Comment créer un graphique en forme de rouge à lèvres avec Matplotlib
- Les 10 meilleurs constructeurs de sites Web AI
- Comment les enseignants exploitent le potentiel de ChatGPT en classe






