Arrêtez le codage dur dans un projet de science des données – utilisez plutôt des fichiers de configuration.
Utilisez des fichiers de configuration pour éviter le codage dur dans un projet de science des données.
Comment interagir efficacement avec les fichiers de configuration en Python.
Problème
Dans votre projet de science des données, certaines valeurs ont tendance à changer fréquemment, telles que les noms de fichiers, les fonctionnalités sélectionnées, le ratio de division des données d’entraînement-test et les hyperparamètres pour votre modèle.

Il est acceptable de coder en dur ces valeurs lors de l’écriture de code ad-hoc pour des tests d’hypothèses ou des démonstrations. Cependant, lorsque votre base de code et votre équipe se développent, il devient essentiel d’éviter le codage en dur car cela peut donner lieu à divers problèmes:
- Cette étude sur l’IA examine l’impact de l’anonymisation pour la formation de modèles de vision par ordinateur, en mettant l’accent sur les ensembles de données de véhicules autonomes.
- Que faire après un B.Tech ?
- Comment l’IA de Meta génère de la musique basée sur une mélodie de référence
- Maintenabilité : Si les valeurs sont dispersées dans toute la base de code, les mettre à jour de manière cohérente devient plus difficile. Cela peut entraîner des erreurs ou des incohérences lorsque les valeurs doivent être mises à jour.
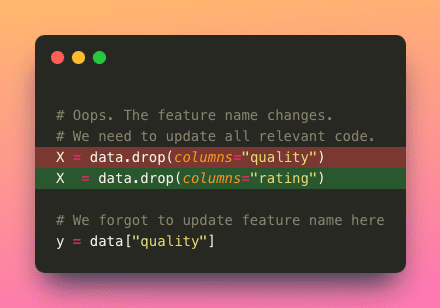
- Réutilisabilité : Le codage en dur des valeurs limite la réutilisabilité du code pour différents scénarios.

- Préoccupations de sécurité : Le codage en dur d’informations sensibles telles que les mots de passe ou les clés d’API directement dans le code peut constituer un risque de sécurité. Si le code est partagé ou exposé, cela pourrait conduire à un accès non autorisé ou à des violations de données.
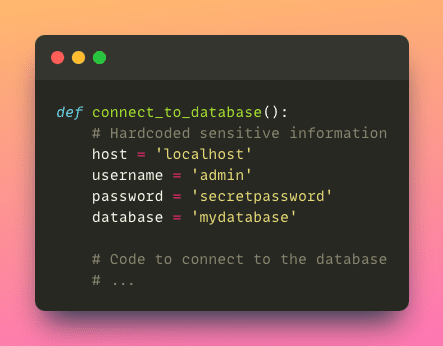
- Tests et débogage : Les valeurs codées en dur peuvent rendre les tests et le débogage plus difficiles. Si les valeurs sont câblées en dur dans le code, il devient difficile de simuler différents scénarios ou de tester efficacement des cas limites.

Solution – Fichiers de configuration
Les fichiers de configuration résolvent ces problèmes en offrant les avantages suivants:
- Séparation de la configuration et du code : Un fichier de configuration vous permet de stocker les paramètres séparément du code, ce qui améliore la maintenabilité et la lisibilité du code.
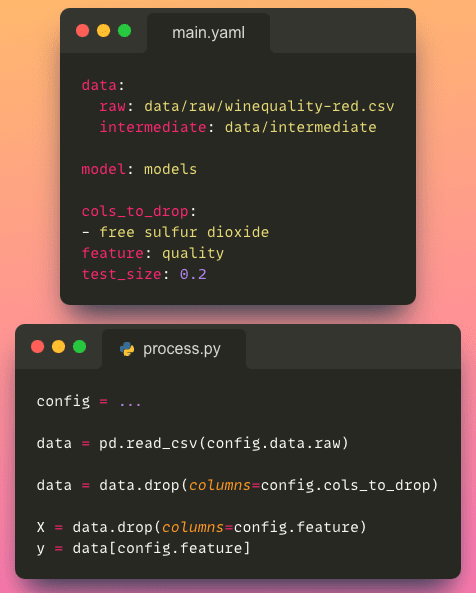
- Flexibilité et modifiabilité : Avec un fichier de configuration, vous pouvez facilement modifier les configurations du projet sans modifier le code lui-même. Cette flexibilité permet une expérimentation rapide, un réglage des paramètres et une adaptation du projet à différents scénarios ou environnements.
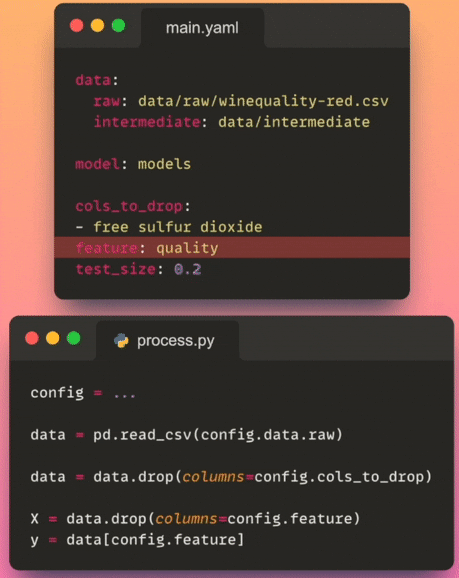
- Contrôle de version : Stocker le fichier de configuration dans un système de contrôle de version vous permet de suivre les modifications apportées à la configuration au fil du temps. Cela permet de maintenir un historique des configurations du projet et facilite la collaboration entre les membres de l’équipe.

- Déploiement et production : Lors du déploiement d’un projet de science des données dans un environnement de production, un fichier de configuration permet une personnalisation facile des paramètres spécifiques à l’environnement de production sans la nécessité de modifier le code. Cette séparation de la configuration et du code simplifie le processus de déploiement.
Introduction à Hydra
Parmi les nombreuses bibliothèques Python disponibles pour la création de fichiers de configuration, Hydra se distingue comme mon outil de gestion de configuration préféré en raison de son impressionnant ensemble de fonctionnalités, notamment:
- Accès pratique aux paramètres
- Remplacement de configuration en ligne de commande
- Composition de configurations à partir de sources multiples
- Exécution de plusieurs tâches avec différentes configurations
Explorons plus en détail chacune de ces fonctionnalités.
N’hésitez pas à jouer et à cloner le code source de cet article ici:
Voir sur GitHub
Accès pratique aux paramètres
Supposons que tous les fichiers de configuration soient stockés sous le dossier conf et que tous les scripts Python soient stockés sous le dossier src.
.
├── conf/
│ └── main.yaml
└── src/
├── __init__.py
├── process.py
└── train_model.pyLe fichier main.yaml ressemble à ceci :

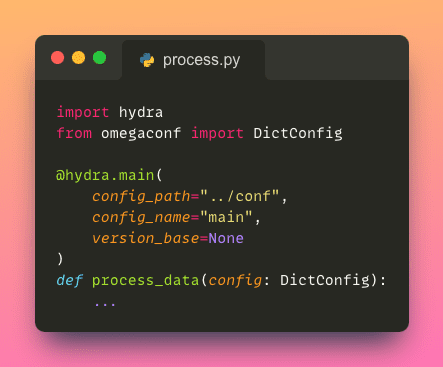
Accéder à un fichier de configuration dans un script Python est aussi simple que d’appliquer un seul décorateur à votre fonction Python.
Pour accéder à un paramètre spécifique du fichier de configuration, nous pouvons utiliser la notation point (par exemple, config.process.cols_to_drop), qui est une méthode plus propre et plus intuitive que d’utiliser des crochets (par exemple, config['process']['cols_to_drop']).
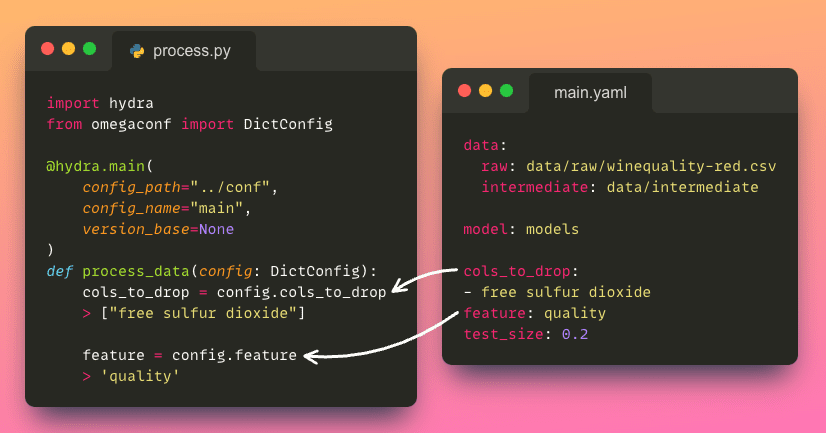
Cette approche simple vous permet de récupérer facilement les paramètres souhaités.
Modification de la configuration en ligne de commande
Disons que vous expérimentez avec différentes valeurs de test_size. Il est fastidieux d’ouvrir plusieurs fois votre fichier de configuration et de modifier la valeur de test_size.

Heureusement, Hydra permet de modifier directement la configuration depuis la ligne de commande. Cette flexibilité permet des ajustements rapides et un affinage sans modifier les fichiers de configuration sous-jacents.

Composition de configurations à partir de sources multiples
Imaginez que vous voulez expérimenter avec diverses combinaisons de méthodes de traitement de données et d’hyperparamètres de modèle. Bien que vous puissiez éditer manuellement le fichier de configuration à chaque fois que vous lancez une nouvelle expérience, cette approche peut prendre du temps.

Hydra permet la composition de configurations à partir de sources multiples avec des groupes de configuration. Pour créer un groupe de configuration pour le traitement des données, créez un répertoire appelé process pour contenir un fichier pour chaque méthode de traitement :
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
└── main.yaml
Si vous voulez utiliser le fichier process1.yaml par défaut, ajoutez-le à la liste par défaut de Hydra.

Suivez les mêmes procédures pour créer un groupe de configuration pour les hyperparamètres de formation :
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
├── train/
│ ├── train1.yaml
│ └── train2.yaml
└── main.yaml
Définissez train1 comme fichier de configuration par défaut :

Maintenant, l’exécution de l’application utilisera les paramètres du fichier process1.yaml et du fichier model1.yaml par défaut :

Cette fonctionnalité est particulièrement utile lorsque différents fichiers de configuration doivent être combinés de manière transparente.
Exécutions multiples
Supposons que vous voulez effectuer des expériences avec plusieurs méthodes de traitement, appliquer chaque configuration une par une peut être fastidieux.

Heureusement, Hydra vous permet d’exécuter la même application avec différentes configurations simultanément.
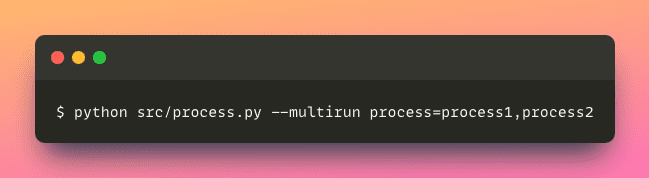
Cette approche rationalise le processus d’exécution d’une application avec divers paramètres, ce qui permet de gagner du temps et des efforts précieux.
Conclusion
Félicitations! Vous venez d’apprendre l’importance de l’utilisation de fichiers de configuration et comment en créer avec Hydra. J’espère que cet article vous donnera les connaissances nécessaires pour créer vos propres fichiers de configuration.
Khuyen Tran est une auteure prolifique de sciences des données et a écrit une impressionnante collection de sujets utiles en sciences des données ainsi que des codes et des articles. Khuyne recherche actuellement un poste d’ingénieur en apprentissage automatique, de scientifique des données ou de défenseur du développement dans la région de la baie après mai 2022, donc n’hésitez pas à la contacter si vous cherchez quelqu’un avec ses compétences.
Original. Reposté avec permission.
We will continue to update IPGirl; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Voxel51 publie en open source VoxelGPT un assistant IA qui exploite la puissance de GPT-3.5 pour générer du code Python pour l’analyse de jeux de données de vision par ordinateur.
- Analyse de séries chronologiques des actions Netflix avec Pandas
- PatchTST Une avancée majeure dans la prévision de séries chronologiques.
- Que fait exactement un scientifique des données ?
- Rétro Data Science Tester les Premières Versions de YOLO
- Comment créer de beaux graphiques de distribution d’âge avec Seaborn et Matplotlib (y compris l’animation)
- Le collectif MIT-Pillar AI annonce les premiers bénéficiaires de subventions initiales.