Dévoiler la puissance de l’ajustement des biais améliorer la précision prédictive dans les jeux de données déséquilibrés
Ajuster les biais pour améliorer la précision prédictive des jeux de données déséquilibrés.
La gestion de l’équilibre des classes est cruciale pour des prédictions précises en science des données. Cet article présente l’Ajustement du Biais pour améliorer la précision du modèle malgré l’équilibre des classes. Découvrez comment l’Ajustement du Biais optimise les prédictions et surmonte ce défi.
Introduction
Dans le domaine de la science des données, la gestion efficace des ensembles de données déséquilibrés est cruciale pour des prédictions précises. Les ensembles de données déséquilibrés, caractérisés par des disparités significatives entre les classes, peuvent conduire à des modèles biaisés favorisant la classe majoritaire et fournissant des performances médiocres pour la classe minoritaire, notamment dans des contextes critiques tels que la détection de fraude et le diagnostic de maladies.
Cet article présente un remède pragmatique connu sous le nom d’Ajustement du Biais. En affinant le terme de biais dans le modèle, il contrecarre le déséquilibre des classes, renforçant ainsi l’aptitude du modèle à effectuer des prédictions précises pour les classes majoritaires et minoritaires. L’article décrit les algorithmes adaptés à la classification binaire et multiclasse, suivis d’une exploration de leurs principes sous-jacents. Notamment, la section “Explication de l’algorithme et principes sous-jacents” établit rigoureusement un lien théorique entre mon algorithme, le sur-échantillonnage et l’ajustement des poids des classes, améliorant la compréhension du lecteur.
Pour étayer l’efficacité et la justification, une étude de simulation examine la relation entre l’Ajustement du Biais et le sur-échantillonnage. De plus, une application pratique est utilisée pour illustrer la mise en œuvre et les avantages tangibles de l’Ajustement du Biais dans la détection de fraudes par carte de crédit.
- Comment extraire les informations clés des documents d’entreprise à l’aide de LayoutLMv3
- Adobe Express améliore l’expérience utilisateur avec Firefly Generative AI
- Les ensembles prompt rendent les LLM plus fiables
L’Ajustement du Biais offre une voie directe et impactante pour affiner les résultats de modélisation prédictive face à un déséquilibre des classes. Cet article offre une compréhension complète du mécanisme, des principes et des implications réelles de l’Ajustement du Biais, en en faisant un outil inestimable pour les scientifiques des données cherchant à améliorer les performances du modèle dans des ensembles de données déséquilibrés.
Algorithm
L’algorithme d’Ajustement du Biais présente une méthodologie pour traiter le déséquilibre des classes dans les tâches de classification binaire et multiclasse. En recalibrant le terme de biais à chaque époque, l’algorithme renforce la capacité du modèle à gérer efficacement les ensembles de données déséquilibrés. En ajustant le terme de biais, l’algorithme rend le modèle plus sensible aux instances de classe minoritaire, améliorant ainsi la précision de la classification.
Modèle f(x) et son rôle dans les prédictions
Le concept de f(x) est au cœur de notre algorithme d’ajustement du biais – un facteur crucial qui guide notre approche pour traiter le déséquilibre des classes. f(x) sert de lien entre les caractéristiques d’entrée x et les prédictions finales. Dans la classification binaire, il agit comme une correspondance qui transforme les entrées en valeurs réelles, alignées avec l’activation sigmoïde pour l’interprétation des probabilités. Dans la classification multiclasse, f(x) se transforme en un ensemble de fonctions, f_k(x), où chaque classe k a sa propre fonction, travaillant en harmonie avec l’activation softmax. Cette distinction est essentielle dans notre algorithme d’ajustement du biais, où nous utilisons f(x) pour ajuster le(s) terme(s) de biais et affiner la sensibilité au déséquilibre des classes.
Aperçu succinct de l’algorithme
Le concept de l’algorithme est simple : calculer la moyenne de f_k(x) pour chaque classe k et représenter cette moyenne comme δk. En soustrayant δk de f_k(x), nous nous assurons que la valeur attendue de f_k(x) – δk devient 0 pour chaque classe k. Par conséquent, le modèle prédit que chaque classe a une probabilité égale de se produire. Bien que cela donne un aperçu concis de la logique de l’algorithme, il est important de noter que cette approche est étayée par des fondements théoriques et mathématiques, qui seront explorés plus en détail dans les sections suivantes de cet article.
Algorithme pour la classification binaire

Utilisation pour la prédiction : Pour effectuer des prédictions, appliquez la dernière valeur de δ calculée par l’algorithme. Cette valeur de δ reflète les ajustements cumulatifs effectués pendant l’entraînement et sert de base pour le terme de biais final dans la fonction d’activation sigmoïde lors de la prédiction.

Algorithme pour la classification multi-classe

Utilisation pour la Prédiction : Le point culminant du processus d’apprentissage de notre algorithme produit un élément crucial — la dernière valeur δk calculée. Cette valeur δk encapsule les ajustements cumulatifs du terme de biais qui ont été méticuleusement orchestrés pendant l’apprentissage. Sa signification réside dans son rôle en tant que paramètre fondamental pour le dernier terme de biais dans la fonction d’activation softmax lors de la prédiction.
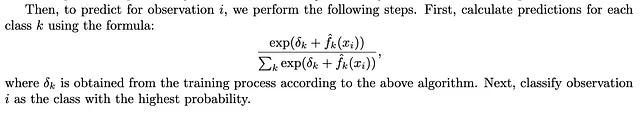
Explication de l’Algorithme et Principes Sous-jacents
De la suréchantillonnage à l’ajustement du poids des classes, de l’ajustement du poids des classes au nouvel algorithme
Dans cette section, nous entreprenons une exploration de l’explication de l’algorithme et des principes sous-jacents. Notre objectif est d’élucider les mécanismes et la logique derrière les opérations de l’algorithme, en fournissant des informations sur son efficacité pour résoudre le déséquilibre des classes dans les tâches de classification.
Fonction de Perte et Déséquilibre
Nous entamons notre voyage en plongeant au cœur de l’algorithme, la fonction de perte. Pour notre exposition initiale, nous examinerons la fonction de perte sans aborder directement la question du déséquilibre des classes. Considérons un problème de classification binaire, où la Classe 1 comprend 90% des observations et la Classe 0 constitue les 10% restants. En désignant l’ensemble des observations de la Classe 1 comme C1 et de la Classe 0 comme C0, nous prenons cela comme point de départ.
La fonction de perte, en l’absence de prise en compte du déséquilibre des classes, prend la forme suivante :
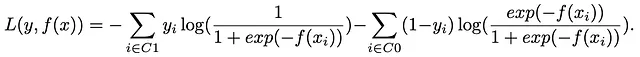
Dans notre quête d’estimation du modèle, nous nous efforçons de minimiser cette fonction de perte :
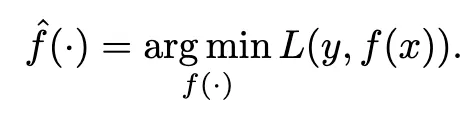
Atténuer le Déséquilibre : Surréchantillonnage et Ajustement du Poids des Classes
Cependant, le cœur de notre entreprise réside dans la résolution du problème du déséquilibre des classes. Pour surmonter ce défi, nous nous aventurons à utiliser des techniques de surréchantillonnage. Bien qu’il existe différentes méthodes de surréchantillonnage, notamment le simple suréchantillonnage, le suréchantillonnage aléatoire, le SMOTE, et d’autres, notre attention, pour plus de clarté dans la présentation, se porte sur le simple suréchantillonnage, avec un aperçu du suréchantillonnage aléatoire.
Simple Surréchantillonnage : Une approche fondamentale dans notre arsenal est le simple suréchantillonnage, une technique où nous dupliquons les instances de la classe minoritaire par un facteur de huit pour égaler la taille de la classe majoritaire. Dans notre exemple illustratif, où la classe minoritaire représente 10% et la classe majoritaire les 90% restants, nous dupliquons les observations de la classe minoritaire huit fois, égalisant ainsi la distribution des classes. En désignant l’ensemble des observations dupliquées comme D0, cette étape transforme notre fonction de perte de la manière suivante :
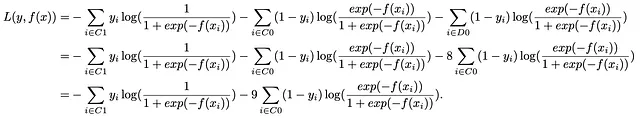
Cela révèle une idée profonde : le principe central du simple suréchantillonnage correspond parfaitement à la notion d’ajustement du poids des classes. La duplication de la classe minoritaire huit fois équivaut effectivement à augmenter le poids de la classe minoritaire neuf fois. Significativement, la technique de surréchantillonnage reflète le mécanisme d’ajustement des poids.
Surréchantillonnage Aléatoire : Une brève réflexion sur le suréchantillonnage aléatoire souligne une observation similaire. Le suréchantillonnage aléatoire, tout comme son homologue plus simple, sert d’équivalent à l’ajustement aléatoire des poids des observations.
De l’Ajustement du Poids des Classes à l’Ajustement du Biais
Une révélation clé souligne le cœur de notre approche : l’équivalence essentielle entre l’ajustement du biais, le suréchantillonnage et l’ajustement des poids. Cette idée émane de
“Prentice et Pyke (1979) … ont montré que, lorsque le modèle contient un terme constant (intercept) pour chaque catégorie, ces termes constants sont les seuls coefficients affectés par la probabilité de sélection inégale du Y” Scott & Wild (1986) [2]. De plus, Manski et Lerman (1977) montrent le même résultat dans le cadre du softmax [1].
Révéler la Signification : En traduisant cette idée dans le domaine de l’apprentissage automatique, le terme constant (intercept) est le terme de biais. Cette observation fondamentale révèle que lorsque nous recalibrons les poids de classe ou les poids d’observation, les changements résultants se manifestent principalement par des ajustements du terme de biais. En d’autres termes, le terme de biais agit comme le point d’ancrage reliant notre stratégie pour résoudre le déséquilibre des classes.
Une Perspective Unifiée
Cette compréhension fournit une explication claire de la façon dont notre algorithme, la suréchantillonnage et l’ajustement des poids sont, en essence, interchangeables et substituables. Cette unification simplifie notre approche tout en maintenant sa puissance pour atténuer les défis du déséquilibre des classes.
Étude de Simulation : Vérification de l’Influence du Terme de Biais par Suréchantillonnage
Pour consolider notre affirmation selon laquelle le suréchantillonnage affecte principalement le terme de biais tout en préservant l’essence fonctionnelle du modèle, nous nous plongeons dans une étude de simulation ciblée. Notre objectif est de démontrer empiriquement comment les techniques de suréchantillonnage impactent uniquement le terme de biais, laissant l’essence du modèle intacte.
La Configuration de la Simulation
Pour cet objectif illustratif, nous nous concentrons sur un scénario simplifié : une régression logistique avec une seule caractéristique. Notre modèle est défini comme suit :
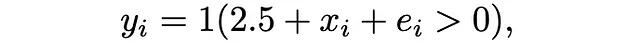
où 1(.) représente la fonction indicatrice, x_i est tiré d’une distribution normale standard et e_i suit une distribution logistique. Dans ce contexte, nous fixons f(x)=x.
Lancement de la Simulation :
En utilisant cette configuration, nous examinons méticuleusement l’impact des techniques de suréchantillonnage sur le terme de biais tout en maintenant le cœur du modèle constant. Nous procédons avec trois méthodes de suréchantillonnage : suréchantillonnage simple, SMOTE et échantillonnage aléatoire. Chaque méthode est appliquée méticuleusement et les résultats sont consciencieusement enregistrés.
Le code Python ci-dessous décrit le processus de simulation :
# Chargement des packagesimport numpy as npimport statsmodels.api as smfrom imblearn.over_sampling import SMOTE, RandomOverSampler# Définition de la graine de génération de nombres aléatoiresnp.random.seed(1)# Création des jeux de données de simulationx = np.random.normal(size = 10000)y = (2.5 + x + np.random.logistic(size = 10000)) > 0# Le terme de biais est fixé à 2.5 et le coefficient x à 1# La taille de la classe 1 est de 9005print(sum(y == 1))# La taille de la classe 0 est de 995print(sum(y == 0))# Nous voulons équilibrer la taille de la classe 0 à celle de la classe 1# Méthode 0 Ne rien fairex0 = xy0 = ymethod0 = sm.Logit(y0, sm.add_constant(x0)).fit()print(method0.summary()) # Terme de biais de 2.54 et coefficient x3 de 0.97# Méthode 1 Suréchantillonnage simplifiéx1 = np.concatenate((x, np.repeat(x[y == 0], 8)))y1 = np.concatenate((y, np.array([0] * (len(x1) - len(x)))))method1 = sm.Logit(y1, sm.add_constant(x1)).fit()print(method1.summary()) # Terme de biais de 0.35 et coefficient x3 de 0.98# Méthode 2 SMOTEsmote = SMOTE(random_state = 1)x2, y2 = smote.fit_resample(x[:, np.newaxis], y)method2 = sm.Logit(y2, sm.add_constant(x2)).fit()print(method2.summary()) # Terme de biais de 0.35 et coefficient x3 de 1# Méthode 3 Échantillonnage aléatoirerandom_sampler = RandomOverSampler(random_state=1)x3, y3 = random_sampler.fit_resample(x[:, np.newaxis], y)method3 = sm.Logit(y3, sm.add_constant(x3)).fit()print(method3.summary()) # Terme de biais de 0.35 et coefficient x3 de 0.99Résultats :
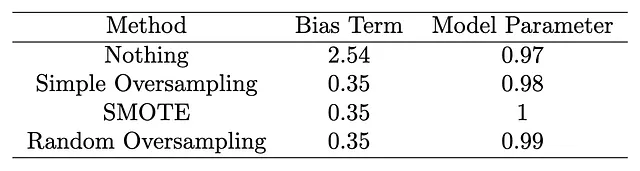
Observations clés
Les résultats de notre étude de simulation valident de manière succincte notre proposition. Malgré l’application de différentes méthodes de suréchantillonnage, la fonction principale du modèle f(x)=x reste inchangée. L’aspect crucial réside dans la remarquable cohérence de la composante du modèle à travers toutes les techniques de suréchantillonnage. Au contraire, le terme de biais présente des variations perceptibles, corroborant notre affirmation selon laquelle le suréchantillonnage affecte principalement le terme de biais sans influencer la structure sous-jacente du modèle.
Renforcement du concept central
Notre étude de simulation souligne indéniablement l’équivalence fondamentale entre le suréchantillonnage, l’ajustement des poids et la modification du terme de biais. En démontrant que le suréchantillonnage modifie exclusivement le terme de biais, nous renforçons le principe selon lequel ces stratégies sont des outils interchangeables dans l’arsenal contre le déséquilibre des classes.
Application de l’algorithme d’ajustement du biais à la détection de fraudes par carte de crédit
Pour démontrer l’efficacité de notre algorithme d’ajustement du biais pour résoudre le déséquilibre des classes, nous utilisons un ensemble de données réelles provenant d’une compétition Kaggle axée sur la détection de fraudes par carte de crédit. Dans ce scénario, le défi consiste à prédire si une transaction par carte de crédit est frauduleuse (étiquetée comme 1) ou non (étiquetée comme 0), étant donné la rareté inhérente des cas de fraude.
Nous commençons par charger les packages essentiels et préparer l’ensemble de données :
import numpy as npimport pandas as pdimport tensorflow as tfimport tensorflow_addons as tfafrom sklearn.model_selection import train_test_splitfrom imblearn.over_sampling import SMOTE, RandomOverSampler# Charger et prétraiter l'ensemble de donnéesdf = pd.read_csv("/kaggle/input/playground-series-s3e4/train.csv")y, x = df.Class, df[df.columns[1:-1]]x = (x - x.min()) / (x.max() - x.min())x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.3, random_state=1)batch_size = 256train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(buffer_size=1024).batch(batch_size)valid_dataset = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)).batch(batch_size)Nous définissons ensuite un modèle d’apprentissage profond simple pour la classification binaire et configurons l’optimiseur, la fonction de perte et la métrique d’évaluation. Nous suivons l’évaluation de la compétition et choisissons l’aire sous la courbe (AUC) comme métrique d’évaluation. De plus, le modèle est intentionnellement simplifié car l’objectif de cet article est de montrer comment mettre en œuvre l’algorithme d’ajustement du biais, et non d’obtenir une prédiction précise :
model = tf.keras.Sequential([ tf.keras.layers.Normalization(), tf.keras.layers.Dense(32, activation='swish'), tf.keras.layers.Dense(32, activation='swish'), tf.keras.layers.Dense(1)])optimizer = tf.keras.optimizers.Adam()loss = tf.keras.losses.BinaryCrossentropy()val_metric = tf.keras.metrics.AUC()Le cœur de notre algorithme d’ajustement du biais réside dans les étapes d’entraînement et de validation, où nous résolvons méticuleusement le déséquilibre des classes. Pour expliquer ce processus, nous nous plongeons dans les mécanismes complexes qui équilibrent les prédictions du modèle.
Étape d’entraînement avec accumulation des valeurs delta
Dans l’étape d’entraînement, nous nous lançons dans le processus qui vise à améliorer la sensibilité du modèle au déséquilibre des classes. Ici, nous calculons et accumulons la somme des sorties du modèle pour deux clusters distincts : delta0 et delta1. Ces clusters revêtent une importance significative, représentant les valeurs prédites associées aux classes 0 et 1, respectivement.
# Définir la fonction d'étape d'entraî[email protected] train_step(x, y): delta0, delta1 = tf.constant(0, dtype = tf.float32), tf.constant(0, dtype = tf.float32) with tf.GradientTape() as tape: logits = model(x, training=True) y_pred = tf.keras.activations.sigmoid(logits) loss_value = loss(y, y_pred) # Calculer le nouveau terme de biais pour résoudre le déséquilibre des classes if len(logits[y == 1]) == 0: delta0 -= (tf.reduce_sum(logits[y == 0])) elif len(logits[y == 0]) == 0: delta1 -= (tf.reduce_sum(logits[y == 1])) else: delta0 -= (tf.reduce_sum(logits[y == 0])) delta1 -= (tf.reduce_sum(logits[y == 1])) grads = tape.gradient(loss_value, model.trainable_weights) optimizer.apply_gradients(zip(grads, model.trainable_weights)) return loss_value, delta0, delta1Étape de validation : Résolution du déséquilibre avec Delta
Les valeurs delta normalisées, dérivées du processus d’entraînement, prennent une place centrale dans l’étape de validation. Armés de ces indicateurs affinés du déséquilibre de classe, nous alignons les prédictions du modèle de manière plus précise avec la répartition réelle des classes. La fonction test_step intègre ces valeurs delta pour ajuster de manière adaptative les prédictions, aboutissant finalement à une évaluation affinée.
@tf.functiondef test_step(x, y, delta): logits = model(x, training=False) y_pred = tf.keras.activations.sigmoid(logits + delta) # Ajuster les prédictions avec delta val_metric.update_state(y, y_pred)Utilisation des valeurs delta pour la correction du déséquilibre
À mesure que l’entraînement progresse, nous recueillons des informations précieuses encapsulées dans les sommes de clusters delta0 et delta1. Ces valeurs cumulatives émergent en tant qu’indicateurs du biais inhérent aux prédictions de notre modèle. À la fin de chaque époque, nous effectuons une transformation vitale. En divisant les sommes cumulées des clusters par le nombre correspondant d’observations de chaque classe, nous obtenons des valeurs delta normalisées. Cette normalisation agit comme un égaliseur essentiel, encapsulant l’essence de notre approche d’ajustement du biais.
E = 1000P = 10B = len(train_dataset)N_class0, N_class1 = sum(y_train == 0), sum(y_train == 1)early_stopping_patience = 0best_metric = 0for epoch in range(E): # init delta delta0, delta1 = tf.constant(0, dtype = tf.float32), tf.constant(0, dtype = tf.float32) print("\nDébut de l'époque %d" % (epoch,)) # Parcourir les lots du jeu de données. for step, (x_batch_train, y_batch_train) in enumerate(train_dataset): loss_value, step_delta0, step_delta1 = train_step(x_batch_train, y_batch_train) # Mettre à jour delta delta0 += step_delta0 delta1 += step_delta1 # Calculer la moyenne de toutes les valeurs delta delta = (delta0/N_class0 + delta1/N_class1)/2 # Exécuter une boucle de validation à la fin de chaque époque. for x_batch_val, y_batch_val in valid_dataset: test_step(x_batch_val, y_batch_val, delta) val_auc = val_metric.result() val_metric.reset_states() print("AUC de validation : %.4f" % (float(val_auc),)) if val_auc > best_metric: best_metric = val_auc early_stopping_patience = 0 else: early_stopping_patience += 1 if early_stopping_patience > P: print("Atteindre la patience d'arrêt précoce. Entraînement terminé avec une AUC de validation : %.4f" % (float(best_metric),)) break;Le Résultat
Dans notre application de détection de fraude par carte de crédit, l’efficacité accrue de notre algorithme se démarque. Grâce à l’intégration transparente de l’ajustement du biais dans le processus d’entraînement, nous obtenons un score AUC impressionnant de 0,77. Cela contraste nettement avec le score AUC de 0,71 obtenu sans l’aide de l’ajustement du biais. L’amélioration profonde des performances prédictives témoigne de la capacité de l’algorithme à naviguer dans les subtilités du déséquilibre de classe, tracant ainsi une voie vers des prédictions plus précises et fiables.
Références
[1] Manski, C. F., & Lerman, S. R. (1977). The estimation of choice probabilities from choice based samples. Econometrica: Journal of the Econometric Society, 1977–1988.
[2] Scott, A. J., & Wild, C. J. (1986). Fitting logistic models under case-control or choice based sampling. Journal of the Royal Statistical Society Series B: Statistical Methodology, 48(2), 170–182.
We will continue to update IPGirl; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Diffusion stable L’IA de la communauté
- Comment utiliser ChatGPT pour convertir du texte en une présentation PowerPoint
- Nouveaux graphiques SHAP Violon et Heatmap
- L’exploitation des LLM avec la recherche d’informations une démonstration simple
- Comment comprendre facilement le code Python des autres?
- Comment accélérer l’inférence jusqu’à 9 fois sur un CPU x86 avec Pytorch
- À l’intérieur de XGen-Image-1 Comment Salesforce Research a construit, entraîné et évalué un modèle massif de traduction de texte en image.