Analyse des performances et optimisation des modèles PyTorch – Partie 3
Performance analysis and optimization of PyTorch models - Part 3
Comment réduire les événements “Cuda Memcpy Async” et pourquoi vous devriez vous méfier des opérations de masque booléen
Ceci est la troisième partie d’une série d’articles sur le thème de l’analyse et de l’optimisation des modèles PyTorch en utilisant PyTorch Profiler et TensorBoard. Notre intention a été de mettre en évidence les avantages du profilage des performances et de l’optimisation des charges de travail d’entraînement basées sur le GPU et leur impact potentiel sur la vitesse et le coût de l’entraînement. En particulier, nous souhaitons démontrer l’accessibilité des outils de profilage tels que PyTorch Profiler et TensorBoard à tous les développeurs ML. Vous n’avez pas besoin d’être un expert en CUDA pour obtenir des gains de performance significatifs en appliquant les techniques que nous discutons dans nos articles.
Dans notre premier article, nous avons démontré comment les différentes vues du plugin TensorBoard de PyTorch Profiler peuvent être utilisées pour identifier les problèmes de performance et avons passé en revue quelques techniques populaires pour accélérer l’entraînement. Dans le deuxième article, nous avons montré comment le plugin TensorBoard Trace View peut être utilisé pour identifier quand les tenseurs sont copiés du CPU au GPU, et vice versa. Ce déplacement de données – qui peut causer des points de synchronisation et ralentir considérablement la vitesse de l’entraînement – est souvent involontaire et peut parfois être facilement évité. Le sujet de cet article sera les situations dans lesquelles nous rencontrons des points de synchronisation entre le GPU et le CPU qui ne sont pas associés à des copies de tenseurs. Tout comme dans le cas des copies de tenseurs, cela peut entraîner une stagnation dans votre étape d’entraînement et ralentir considérablement la durée totale de votre entraînement. Nous démontrerons l’existence de ces occurrences, comment les identifier à l’aide de PyTorch Profiler et du plugin TensorBoard de PyTorch Profiler Trace View, et les avantages potentiels en termes de performances de construire votre modèle de manière à minimiser de tels événements de synchronisation.
Tout comme dans nos articles précédents, nous définirons un modèle PyTorch basique et ensuite nous profilerons ses performances de manière itérative, identifierons les goulots d’étranglement et tenterons de les résoudre. Nous exécuterons nos expériences sur une instance Amazon EC2 g5.2xlarge (contenant un GPU NVIDIA A10G et 8 vCPUs) en utilisant l’image Docker officielle AWS PyTorch 2.0. Gardez à l’esprit que certains des comportements que nous décrivons peuvent varier entre les versions de PyTorch.
Exemple de jouet
Dans les blocs suivants, nous présentons un modèle PyTorch de jouet qui effectue une segmentation sémantique sur une image d’entrée de 256×256, c’est-à-dire qu’il prend une image RVB de 256×256 et produit une carte de 256×256 de “labels par pixel” à partir d’une classe de dix catégories sémantiques.
- Classification de texte avec des encodeurs Transformer
- Transformée de Fourier pour les séries temporelles décalage de tendance
- Conseils pratiques pour améliorer l’analyse exploratoire de données
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optimimport torch.profilerimport torch.utils.datafrom torch import Tensorclass Net(nn.Module): def __init__(self, num_hidden=10, num_classes=10): super().__init__() self.conv_in = nn.Conv2d(3, 10, 3, padding='same') hidden = [] for i in range(num_hidden): hidden.append(nn.Conv2d(10, 10, 3, padding='same')) hidden.append(nn.ReLU()) self.hidden = nn.Sequential(*hidden) self.conv_out = nn.Conv2d(10, num_classes, 3, padding='same') def forward(self, x): x = F.relu(self.conv_in(x)) x = self.hidden(x) x = self.conv_out(x) return xPour entraîner notre modèle, nous utiliserons la perte d’entropie croisée standard avec quelques modifications :
- Nous supposerons que les étiquettes cibles incluent une valeur d’ignorance indiquant les pixels que nous voulons exclure du calcul de la perte.
- Nous supposerons qu’une des étiquettes sémantiques identifie certains pixels comme appartenant à l’arrière-plan de l’image. Nous définissons notre fonction de perte pour traiter ceux-ci comme des étiquettes à ignorer.
- Nous mettrons à jour les poids de notre modèle uniquement lorsque nous rencontrerons des lots avec des tenseurs cibles comprenant au moins deux valeurs uniques.
Alors que nous avons choisi ces modifications à des fins de démonstration, ces types d’opérations ne sont pas rares et peuvent être trouvés dans de nombreux modèles PyTorch “standards”. Étant donné que nous sommes déjà des “experts” en profilage des performances, nous avons déjà enveloppé chacune des opérations de notre fonction de perte avec un gestionnaire de contexte torch.profiler.record_function (comme décrit dans notre deuxième article).
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss() def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: # créer un masque booléen des étiquettes valides with torch.profiler.record_function('create mask'): mask = target != self.ignore_val # permuter les logits en préparation pour le masquage with torch.profiler.record_function('permute'): permuted_pred = torch.permute(pred, [0, 2, 3, 1]) # appliquer le masque booléen aux cibles et aux logits with torch.profiler.record_function('mask'): masked_target = target[mask] masked_pred = permuted_pred[mask.unsqueeze(-1).expand(-1, -1, -1, self.num_classes)] masked_pred = masked_pred.reshape(-1, self.num_classes) # calculer la perte de l'entropie croisée with torch.profiler.record_function('calc loss'): loss = self.loss(masked_pred, masked_target) return loss def ignore_background(self, target: Tensor) -> Tensor: # découvrir tous les indices où l'étiquette cible est "background" with torch.profiler.record_function('non_zero'): inds = torch.nonzero(target == self.num_classes - 1, as_tuple=True) # réinitialiser toutes les étiquettes "background" à l'indice d'ignorance with torch.profiler.record_function('index assignment'): target[inds] = self.ignore_val return target def forward(self, pred: Tensor, target: Tensor) -> Tensor: # ignorer les étiquettes d'arrière-plan target = self.ignore_background(target) # récupérer une liste d'éléments uniques dans la cible with torch.profiler.record_function('unique'): unique = torch.unique(target) # vérifier si le nombre d'éléments uniques dépasse le seuil with torch.profiler.record_function('numel'): ignore_loss = torch.numel(unique) < 2 # calculer la perte de l'entropie croisée loss = self.cross_entropy(pred, target) # mettre la perte à zéro dans le cas où le nombre d'éléments uniques # est inférieur au seuil if ignore_loss: loss = 0. * loss return lossNotre fonction de perte semble assez innocente, n’est-ce pas ? Faux ! Comme nous le verrons ci-dessous, la fonction de perte comprend un certain nombre d’opérations qui déclenchent des événements de synchronisation hôte-appareil qui ralentissent considérablement la vitesse d’entraînement, sans copier de tenseurs vers ou depuis le GPU. Comme dans notre précédent article, nous vous mettons au défi d’essayer d’identifier trois opportunités d’optimisation des performances avant de continuer à lire.
Pour les besoins de notre démonstration, nous utilisons des images générées aléatoirement et des cartes d’étiquettes par pixel, comme défini ci-dessous.
from torch.utils.data import Dataset# Un ensemble de données avec des images aléatoires et des cartes d'étiquettesclass FakeDataset(Dataset): def __init__(self, num_classes=10): super().__init__() self.num_classes = num_classes self.img_size = [256, 256] def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3]+self.img_size, dtype=torch.float32) rand_label = torch.randint(low=-1, high=self.num_classes, size=self.img_size) return rand_image, rand_labeltrain_set = FakeDataset()train_loader = torch.utils.data.DataLoader(train_set, batch_size=256, shuffle=True, num_workers=8, pin_memory=True)Enfin, nous définissons notre étape d’entraînement avec le profil Profiler de PyTorch configuré selon nos souhaits :
device = torch.device("cuda:0")model = Net().cuda(device)criterion = MaskedLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# boucle d'entraînement enveloppée dans un objet profilerwith torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/prof'), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, data in enumerate(train_loader): inputs = data[0].to(device=device, non_blocking=True) labels = data[1].to(device=device, non_blocking=True) if step >= (1 + 4 + 3) * 1: break outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step() prof.step()Si vous exécutez naïvement ce script d’entraînement, vous verrez probablement une utilisation élevée du GPU (~90%) et vous ne saurez pas qu’il y a quelque chose qui ne va pas. Ce n’est qu’en effectuant un profilage que nous pouvons identifier les goulots d’étranglement de performance sous-jacents et les opportunités potentielles pour accélérer l’entraînement. Donc, sans plus tarder, voyons comment notre modèle se comporte.
Résultats de performance initiaux
Dans cet article, nous nous concentrerons sur la vue de traçage du plugin TensorBoard du profilateur PyTorch. Veuillez consulter nos articles précédents pour des conseils sur l’utilisation des autres vues prises en charge par le plugin.
Dans l’image ci-dessous, nous montrons la vue de traçage d’une seule étape d’entraînement de notre modèle jouet.
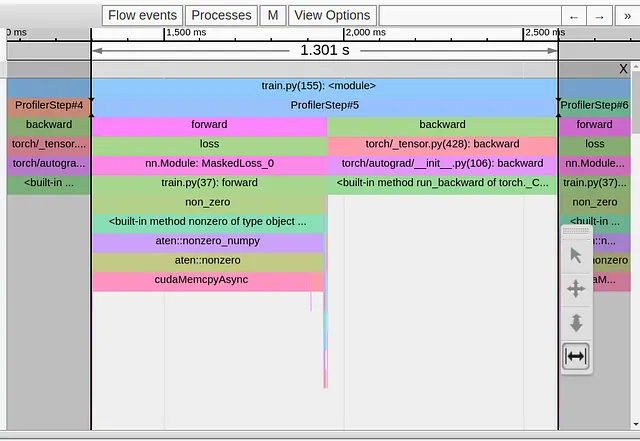
Nous pouvons clairement voir que notre étape d’entraînement d’une durée de 1,3 seconde est complètement dominée par l’opérateur torch.nonzero dans la première ligne de notre fonction de perte. Toutes les autres opérations sont regroupées de part et d’autre de l’événement cudaMemcpyAsyn énorme. Que se passe-t-il ??!! Pourquoi une opération en apparence anodine causerait-elle un tel désagrément ?
Il est possible que nous ne devrions pas être si surpris, car la documentation de torch.nonzero inclut la note suivante : “Lorsque input est sur CUDA, torch.nonzero() provoque une synchronisation hôte-périphérique.” La nécessité de synchronisation découle du fait que, contrairement à d’autres opérations courantes de PyTorch, la taille du tenseur renvoyé par torch.nonzero n’est pas prédéterminée. Le CPU ne sait pas combien d’éléments non nuls il y a dans le tenseur d’entrée à l’avance. Il doit attendre l’événement de synchronisation du GPU pour effectuer l’allocation appropriée de mémoire GPU et préparer correctement les opérations PyTorch ultérieures.
Notez que la durée de cudaMempyAsync n’indique pas la complexité de l’opération torch.nonzero, mais reflète plutôt le temps que le CPU doit attendre que le GPU termine tous les noyaux précédents que le CPU a lancés. Par exemple, si nous effectuons un appel torch.nonzero supplémentaire immédiatement après le premier, notre deuxième événement cudaMempyAsync apparaîtrait considérablement plus court que le premier, car le CPU et le GPU sont déjà plus ou moins “synchronisés”. (Gardez à l’esprit que cette explication provient d’un non-expert en CUDA, donc faites-en ce que vous voulez…)
Optimisation #1 : Réduire l’utilisation de l’opération torch.nonzero
Maintenant que nous comprenons la source du goulot d’étranglement, le défi consiste à trouver une séquence alternative d’opérations qui effectue la même logique mais qui ne déclenche pas un événement de synchronisation hôte-périphérique. Dans le cas de notre fonction de perte, nous pouvons facilement y parvenir en utilisant l’opérateur torch.where comme illustré dans le bloc de code ci-dessous :
def ignore_background(self, target: Tensor) -> Tensor: with torch.profiler.record_function('update background'): target = torch.where(target==self.num_classes-1, -1*torch.ones_like(target),target) return targetDans l’image ci-dessous, nous montrons la vue de traçage après ce changement.
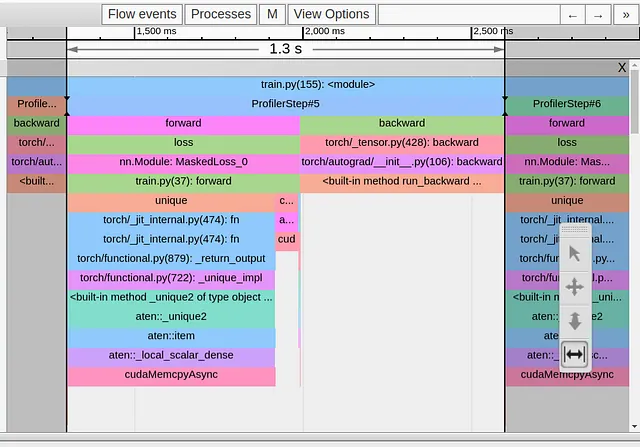
Alors que nous avons réussi à supprimer le cudaMempyAsync provenant de l’opération torch.nonzero, il a été immédiatement remplacé par un autre provenant de l’opération torch.unique, et notre temps d’exécution n’a pas bougé. Ici, la documentation de PyTorch est moins aimable, mais sur la base de notre expérience précédente, nous pouvons supposer que, une fois de plus, nous subissons un événement de synchronisation hôte-périphérique en raison de notre utilisation de tenseurs de taille indéterminée.
Optimisation #2 : Réduire l’utilisation de l’opération torch.unique
Remplacer l’opérateur torch.unique par une alternative équivalente n’est pas toujours possible. Cependant, dans notre cas, nous n’avons pas réellement besoin de connaître les valeurs des étiquettes uniques, nous avons seulement besoin de connaître le nombre d’étiquettes uniques. Cela peut être calculé en appliquant l’opération torch.sort sur le tenseur cible aplati et en comptant le nombre d’étapes dans la fonction d’étape résultante.
def forward(self, pred: Tensor, target: Tensor) -> Tensor: # ignorer les étiquettes d'arrière-plan target = self.ignore_background(target) # trier la liste des étiquettes with torch.profiler.record_function('tri'): sorted,_ = torch.sort(target.flatten()) # identifier les étapes de la fonction d'étape résultante with torch.profiler.record_function('deriv'): deriv = sorted[1:]-sorted[:-1] # compter le nombre d'étapes with torch.profiler.record_function('count_nonzero'): num_unique = torch.count_nonzero(deriv)+1 # calculer la perte de l'entropie croisée loss = self.cross_entropy(pred, target) # mettre la perte à zéro dans le cas où le nombre d'éléments uniques # est inférieur au seuil with torch.profiler.record_function('where'): loss = torch.where(num_unique<2, 0.*loss, loss) return lossDans l’image ci-dessous, nous capturons la vue de trace après notre deuxième optimisation :
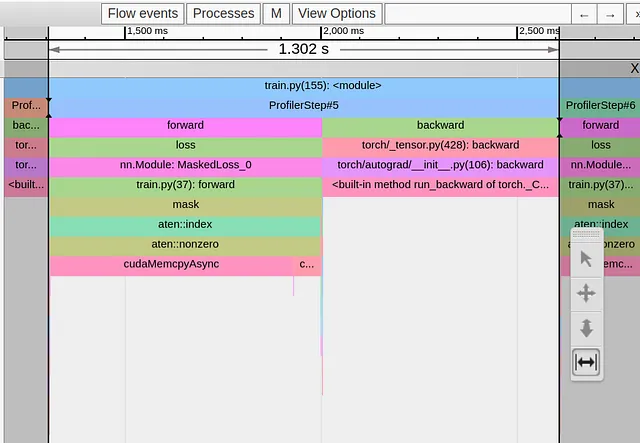
Une fois de plus, nous avons résolu un goulot d’étranglement pour en rencontrer un nouveau, cette fois-ci provenant de la routine de masquage booléen.
Le masquage booléen est une routine que nous utilisons couramment pour réduire le nombre total d’opérations machine requises. Dans notre cas, notre intention était de réduire le calcul en supprimant les pixels “ignorés” et en limitant le calcul de l’entropie croisée aux pixels d’intérêt. Clairement, cela a échoué. Comme précédemment, l’application d’un masque booléen donne un tenseur de taille indéterminée, et le cudaMempyAsync qu’il déclenche est largement supérieur à toutes les économies réalisées en excluant les pixels “ignorés”.
Optimisation #3 : Méfiez-vous des opérations de masquage booléen
Dans notre cas, corriger ce problème est plutôt simple car la fonction CrossEntropyLoss de PyTorch a une option intégrée pour définir un ignore_index.
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: with torch.profiler.record_function('calc loss'): loss = self.loss(pred, target) return lossDans l’image ci-dessous, nous montrons la vue de trace résultante :

Mince alors !! Notre temps d’étape a chuté à seulement 5,4 millisecondes. C’est 240 fois plus rapide qu’au départ. En modifiant simplement quelques appels de fonction et sans aucune modification de la logique de la fonction de perte, nous avons pu optimiser considérablement les performances de l’étape d’entraînement.
Note importante : Dans l’exemple que nous avons choisi, les étapes que nous avons prises pour réduire le nombre d’événements cudaMempyAsync ont eu un impact clair sur le temps de l’étape d’entraînement. Cependant, il peut y avoir des situations où les mêmes types de modifications nuiront aux performances plutôt que de les améliorer. Par exemple, dans le cas du masquage booléen, si notre masque est extrêmement dispersé et que les tenseurs d’origine sont extrêmement grands, les économies de calcul résultant de l’application du masque peuvent l’emporter sur le coût de la synchronisation hôte-appareil. Il est important d’évaluer l’impact de chaque optimisation au cas par cas.
Résumé
Dans cet article, nous nous sommes concentrés sur les problèmes de performances dans les applications d’entraînement causés par des événements de synchronisation hôte-appareil. Nous avons vu plusieurs exemples d’opérateurs PyTorch qui déclenchent de tels événements – leur propriété commune étant que la taille des tenseurs qu’ils produisent dépend de l’entrée. Vous pouvez également rencontrer des événements de synchronisation à partir d’autres opérateurs, non couverts dans cet article. Nous avons démontré comment des analyseurs de performances tels que le Profiler PyTorch et son plugin TensorBoard associé peuvent être utilisés pour identifier ce type d’événements.
Dans le cas de notre exemple de jouet, nous avons pu trouver des alternatives équivalentes aux opérateurs problématiques qui utilisent des tenseurs de taille fixe et évitent le besoin d’événements de synchronisation. Cela a conduit à une amélioration significative du temps d’entraînement. Cependant, en pratique, il peut être beaucoup plus difficile, voire impossible, de résoudre ce type de goulots d’étranglement. Parfois, les surmonter peut nécessiter une refonte de certaines parties de votre modèle.
We will continue to update IPGirl; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Métriques d’évaluation pour les systèmes de recommandation – Un aperçu
- Avancée dans l’intersection de la vision et du langage Présentation du projet Tout-Voyant
- Padding des grands modèles de langage – Exemples avec Llama 2
- Affinage d’un modèle Llama-2 7B pour la génération de code Python
- Un guide complet sur MLOps
- Des expériences 🧪 au déploiement 🚀 MLflow 101 | Partie 02
- AdaTape Modèle de base avec calcul adaptatif et lecture-écriture dynamique






