Comment créer un système de notation Elo basé sur les données pour les jeux en 2 contre 2
Système de notation Elo pour jeux 2v2 basé sur données
Mettre les maths sur la table : des algorithmes à la folie du baby-foot, la quête du champion ultime du bureau.
Bonjour et bienvenue !
Je m’appelle Lazare et je viens de terminer ma deuxième licence en Analyse de Données d’Entreprise. Cet article est basé sur le travail que j’ai réalisé pour ma thèse de licence.
Des matchs amicaux à la compétition intense, le baby-foot a trouvé sa place dans la culture d’entreprise, offrant une façon unique aux équipes de se connecter et de rivaliser.
Cet article explore les mathématiques derrière un système de notation basé sur l’Elo en 2 contre 2 qui peut être appliqué au baby-foot ou à n’importe quel autre jeu en 2 contre 2. Il examine également l’architecture qui soutient le traitement des données et présente la création d’une application web qui fournit un classement en temps réel et une analyse des données en utilisant Python.
- Un guide sur les concepts fondamentaux dont vous avez besoin pour commencer à effectuer des tests statistiques
- Comment pouvons-nous mesurer l’incertitude dans les champs de radiance neuronaux ? Présentation de BayesRays un cadre révolutionnaire post-hoc pour les NeRFs
- Commencer avec SQL en 5 étapes
Le classement Elo
Le système de notation Elo est une méthode utilisée pour déterminer le niveau de compétence relative d’un joueur dans des jeux à somme nulle. Il a été développé pour la première fois pour les échecs, mais il est maintenant utilisé comme système de notation dans une variété d’autres sports tels que le baseball, le basket-ball, divers jeux de société et les sports électroniques.
Un exemple bien connu de ce système se trouve dans les échecs, où le système de notation Elo est utilisé pour classer les joueurs du monde entier. Magnus Carlsen, également connu sous le nom de “Mozart des échecs”, détient le plus haut classement Elo au monde avec une note de 2 853 en 2023, démontrant ses compétences extraordinaires dans le jeu.
La formule de notation Elo est une formule en deux parties : d’abord, elle calcule le résultat attendu pour un groupe donné de joueurs, puis elle détermine l’ajustement de notation en fonction du résultat du match et du résultat attendu.
Calcul du Résultat Attendu
Prenons l’exemple suivant aux échecs avec les joueurs A et B ayant respectivement les notes R𝖠 et R𝖡. L’équation pour le score attendu du joueur A contre le joueur B est la suivante :
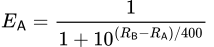
L’algorithme Elo utilise une variable qui peut être ajustée pour contrôler la façon dont la probabilité de victoire est influencée par les notes des joueurs. Dans cet exemple, elle est fixée à 400, ce qui est typique pour la plupart des sports, y compris les échecs.
Jetons maintenant un coup d’œil à un exemple plus réaliste, où le joueur A a une note de 1 500 et le joueur B, 1 200.
La même équation vue ci-dessus peut calculer le score attendu du joueur A contre le joueur B :
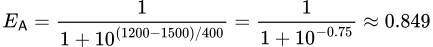
Avec ce calcul, nous savons que le joueur A a 84,9% de chances de gagner contre le joueur B.
Pour trouver la probabilité estimée que le joueur B gagne contre le joueur A, la même formule est utilisée, mais l’ordre des notes est inversé :
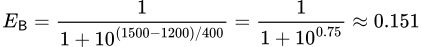
La somme des probabilités de victoire du joueur A et de victoire du joueur B est égale à 1 (0,849 + 0,151 = 1). Dans ce scénario, le joueur A a donc 84,9% de chances de gagner, laissant au joueur B seulement 15,1% de chances.
Calcul de la Notation
La différence de notation entre le gagnant et le perdant détermine le nombre total de points gagnés ou perdus après chaque partie.
- Si un joueur avec une notation Elo beaucoup plus élevée gagne, il recevra moins de points pour sa victoire et son adversaire en perdra seulement quelques points pour sa défaite.
- En revanche, si le joueur moins bien classé gagne, cet exploit est considéré comme beaucoup plus important, la récompense est donc plus grande et l’adversaire mieux classé est pénalisé en conséquence.
La formule pour calculer le nouveau classement du joueur A jouant contre le joueur B est la suivante :
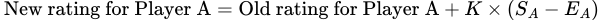
Dans cette formule, ( S𝖠 — E𝖠 ) représente la différence entre le score réel du joueur A et le score attendu. La variable supplémentaire K détermine approximativement combien le classement d’un joueur peut changer après un seul match. Aux échecs, cette variable est fixée à 32.
Si le joueur A gagne, le score réel, qui est de 1 dans ce cas, sera supérieur au score attendu de 0,849, créant ainsi une variance positive.
Cela indique que le joueur A a mieux performé que prévu initialement. En conséquence, le système de classement Elo recalcule les classements pour les deux joueurs :
- Le classement du joueur A augmentera en raison de la victoire
- Le classement du joueur B diminuera en raison de la défaite
Encore une fois, cette même équation peut calculer le nouveau classement du joueur A et du joueur B :
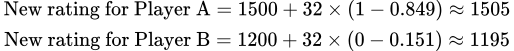
En résumé, le système de classement Elo offre une méthode robuste et efficace pour évaluer et comparer dynamiquement et équitablement les compétences des joueurs. Il met à jour continuellement le classement d’un joueur après chaque match, en tenant compte de la différence de compétence entre les deux adversaires.
Cette approche récompense la prise de risque, car gagner contre un joueur mieux classé entraîne une augmentation plus significative du classement d’un joueur, comme le montre le tableau ci-dessous :
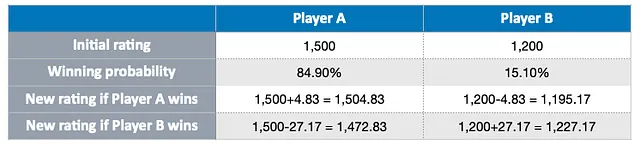
En revanche, si un joueur mieux classé va à l’encontre de sa probabilité de gagner et perd contre un joueur moins bien classé, son classement sera significativement impacté : il perdra plus de points et son adversaire en gagnera davantage.
En résumé, lorsque qu’un joueur remporte un match, plus sa probabilité de victoire est faible, plus il peut gagner de points.
Dans son état actuel, cette formule de classement, initialement conçue pour les échecs, n’est pas entièrement adaptée au baby-foot.
En effet, le baby-foot comporte plus de variables que les échecs, telles que :
- Il s’agit d’un jeu à quatre joueurs avec des équipes de deux personnes (2v2)
- Chaque membre de l’équipe peut influencer positivement ou négativement son coéquipier
- Contrairement au résultat binaire aux échecs, l’ampleur de la victoire ou de la défaite au baby-foot peut varier considérablement en fonction des scores des équipes
Exploration de l’algorithme de classement
L’objectif ici est d’adapter le système de classement Elo aux exigences particulières des parties de baby-foot, impliquant quatre joueurs répartis en deux équipes.
Probabilité de victoire
Pour commencer à calculer les nouveaux classements des joueurs, il est nécessaire d’établir une formule affinée pour déterminer le résultat attendu d’une partie impliquant quatre joueurs répartis en deux équipes.
Pour illustrer cela, considérons un scénario hypothétique de partie de baby-foot avec quatre joueurs : Joueur 1, Joueur 2, Joueur 3 et Joueur 4, chacun ayant un classement différent qui représente leur niveau de compétence.

Pour calculer le score attendu de l’Équipe 1 contre l’Équipe 2 dans le système de classement Elo révisé, il faut déterminer le score attendu de chaque joueur participant à la partie.
Le classement attendu du Joueur 1, noté E𝖯𝟣, peut être calculé en faisant la moyenne de la somme des classements de chaque adversaire en utilisant la formule de classement Elo comme suit :
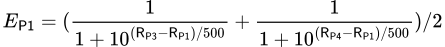
Après des tests approfondis, il a été décidé qu’il serait approprié pour la formule du score attendu de définir la variable utilisée pour diviser la différence de classement à 500, plutôt que la valeur traditionnelle de 400 utilisée aux échecs. Cette valeur accrue signifie que le classement d’un joueur aura un impact moindre sur son score attendu.
Une raison principale de cet ajustement est que, contrairement aux échecs, il y a un léger élément de chance au baby-foot. En utilisant une valeur de 500, les résultats des parties peuvent être prédits de manière plus précise et un système de classement fiable peut être développé.
Pour calculer le score attendu du Joueur 2 désigné par E𝖯𝟤, contre le Joueur 3 et le Joueur 4, la même méthode que celle utilisée pour le Joueur 1 peut être employée.
Le score attendu de l’Équipe désigné E𝖳𝟣 peut ensuite être calculé en prenant la moyenne de E𝖯𝟣 et E𝖯𝟤 :

Une fois les scores attendus pour chaque joueur calculés, ils peuvent ensuite être utilisés pour déterminer le résultat de la partie. L’équipe ayant le score attendu le plus élevé a plus de chances de gagner. En calculant la moyenne des scores attendus pour chaque membre de l’équipe, le problème des différences de compétence au sein de l’équipe peut être résolu !
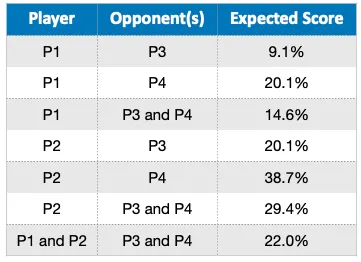
Le tableau ci-dessous montre les scores attendus du Joueur 1 et du Joueur 2 contre les Joueurs 3 et 4.
- Les scores attendus de P1 contre P3 et P4 sont de 0,091 et 0,201, correspondant à une chance de gagner de 14,6%
- Les scores attendus de P2 contre P3 et P4 sont de 0,201 et 0,387, donnant une probabilité de victoire combinée de 29,4%
- Pour P1, faire équipe avec un joueur plus fort comme P2 peut augmenter ses chances globales de gagner, comme le démontre le 22%
Si l’équipe de P1 et P2 gagne, P1 gagne moins de points que ce que son score attendu individuel suggérerait, car P2, qui a un classement plus élevé, contribue également à la victoire et réduit ainsi sa probabilité globale de victoire.
En revanche, P2 gagne plus de points en raison d’un coéquipier moins bien classé. En cas de victoire, P2 est récompensé pour avoir pris un risque, tandis que P1 gagne moins de points, car on suppose que P2 a contribué de manière significative à la victoire, et vice versa en cas de défaite.
Paramètres de Classement
Maintenant que le résultat attendu d’une partie à quatre joueurs a été déterminé, ces informations peuvent être intégrées dans une nouvelle formule qui prend en compte plusieurs variables qui affectent la partie et les classements des joueurs.
Comme discuté précédemment, la valeur K peut être modifiée pour mieux correspondre aux besoins du système de classement. Cette nouvelle formule prend en compte le nombre de parties jouées par chaque joueur, reflétant leur ancienneté ainsi que le résultat de la partie.
Par exemple, lors de la demi-finale de la Coupe du Monde 2014, l’Allemagne a battu le Brésil sur le score de 7-1. Il s’agissait d’un des résultats les plus choquants et humiliants de l’histoire de la Coupe du Monde, car le Brésil était le pays hôte et n’avait jamais perdu de match compétitif à domicile depuis 1975.
Si nous devions appliquer le système de classement à cette partie, nous nous attendrions à ce que l’Allemagne gagne un nombre important de points, tandis que le Brésil en perdrait beaucoup, reflétant la différence de performance et de niveau de compétence entre les deux équipes.
Valeur KLa valeur K, désignée par K𝟣 pour le Joueur 1 dans ce cas, détermine dans quelle mesure le classement d’un joueur changera après une partie. Cette valeur K révisée prend en compte le nombre de parties jouées par le joueur pour équilibrer l’effet de chaque partie sur son classement. Après de nombreux tests, une formule a été développée pour calculer la valeur K pour chaque joueur.
Pour le Joueur 1, cela s’exprime comme suit :
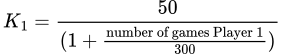
Cette formule pour la valeur K est conçue pour avoir un impact plus important sur la notation des nouveaux joueurs tout en offrant une stabilité et moins de fluctuation de la notation pour les joueurs expérimentés. Plus précisément, après avoir joué 300 parties, la notation d’un joueur devient plus représentative de son niveau de compétence.
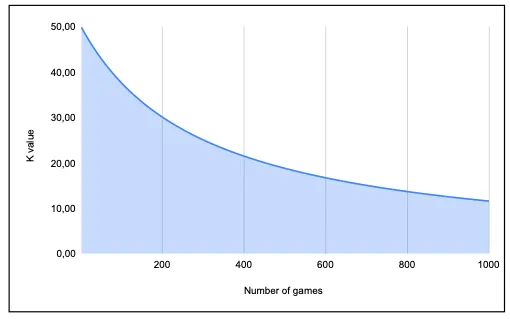
La figure IV montre l’effet du nombre de parties jouées sur la valeur K. À partir de 50, ce graphique montre que la valeur K diminue à mesure que le nombre de parties jouées augmente, atteignant une valeur réduite de moitié, soit 25, après 300 parties. Cela garantit que l’impact de chaque partie sur la notation d’un joueur diminue à mesure que l’expérience augmente.
Facteur de pointsPour prendre en compte les points marqués par chaque équipe, une nouvelle variable, appelée “facteur de points”, a été introduite dans l’équation. Ce facteur multiplie le paramètre K de chaque joueur et est basé sur la différence absolue de points entre les deux équipes. L’impact d’un match doit être plus important lorsqu’une équipe remporte une victoire écrasante.
Pour calculer le facteur de points, la formule suivante a été utilisée :
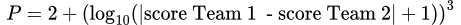
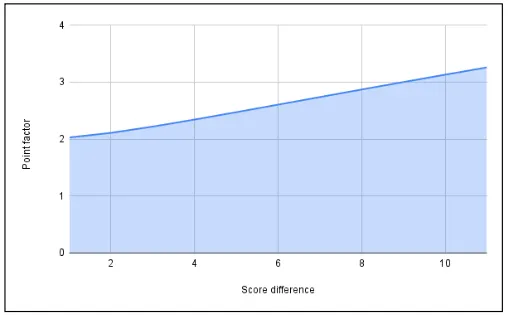
Cette formule prend la différence absolue entre les scores des deux équipes, ajoute 1, et calcule le logarithme décimal du résultat. Cette valeur est ensuite élevée au cube et 2 est ajouté au résultat pour obtenir la valeur finale du facteur de points.
Calcul de la notation finale
Après avoir ajusté toutes les variables nécessaires, une formule améliorée a été développée pour calculer le nouveau classement de chaque joueur impliqué dans un match.
La notation de chaque joueur prend maintenant en compte sa notation précédente, la notation de ses adversaires, l’impact de ses coéquipiers, son historique de jeu et le score du match. Cette formule garantit que chaque joueur est récompensé en fonction de sa véritable performance, en tenant compte de l’équité de chaque match.
En reprenant l’exemple précédent, la nouvelle formule pour le classement du joueur A est la suivante :
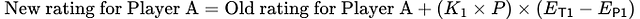
Cette formule améliorée récompense les joueurs en fonction de leur performance réelle, encourage la prise de risques et offre un système de notation plus équilibré pour les nouveaux joueurs et les joueurs expérimentés.
Maintenant que nous avons un algorithme Elo, passons à la modélisation de la base de données.
Conception et modélisation de la base de données
Le modèle de base de données proposé adopte une approche relationnelle, organisant les données en tables interconnectées grâce à l’utilisation de clés primaires (PK) et de clés étrangères (FK). Cette organisation structurée facilite la gestion et l’analyse des données, ce qui fait de PostgreSQL un choix approprié en tant que système de gestion de base de données. Les clés primaires et étrangères aident à maintenir la cohérence des données et à minimiser la redondance dans la base de données.
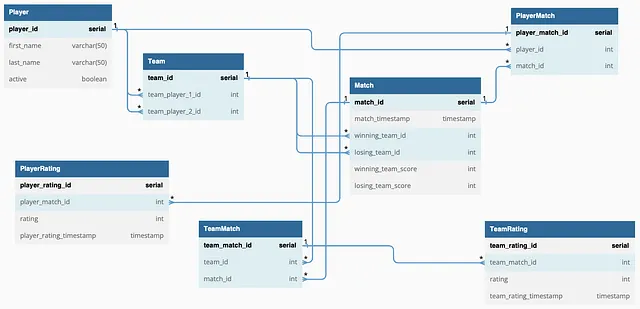
Deux types de relations existent entre les tables de ce modèle de base de données : un-à-plusieurs et plusieurs-à-plusieurs.
La relation entre la table ‘Joueur’ et la table ‘Match’ est plusieurs-à-plusieurs, car un joueur peut participer à de nombreuses parties et plusieurs joueurs peuvent être impliqués dans une seule partie. Une table de jonction appelée ‘JoueurMatch’ établit le lien entre ces deux tables, contenant deux clés étrangères : ‘player_id’ (référençant le joueur participant) et ‘match_id’ (référençant le match correspondant).
Cette structure assure l’association précise des joueurs et des matches, comme le montre le code ci-dessous :
CREATE TABLE PlayerMatch (player_match_id serial PRIMARY KEY,player_id INT NOT NULL REFERENCES Player(player_id),match_id INT NOT NULL REFERENCES Match(match_id));Une logique similaire s’applique à la table ‘TeamMatch’, qui sert de jonction entre les tables ‘Match’ et ‘Team’, permettant à plusieurs équipes de jouer un match et à un match d’impliquer plusieurs équipes.
Des tables distinctes pour ‘PlayerRating’ et ‘TeamRating’ ont été conçues pour rationaliser l’analyse du classement au fil du temps. Ces tables se connectent respectivement aux tables ‘PlayerMatch’ et ‘TeamMatch’ via ‘player_match_id’ et ‘team_match_id’.
Intégrité des données
En plus de l’utilisation de PKs et de FKs, ce modèle de base de données utilise également des types de données appropriés et des contraintes CHECK pour garantir l’intégrité des données :
- Les colonnes ‘winning_team_score’ et ‘losing_team_score’ de la table ‘Match’ sont des entiers, empêchant les entrées non numériques
- Les contraintes CHECK imposent que ‘winning_team_score’ soit exactement 11
- Les contraintes CHECK imposent que ‘losing_team_score’ soit compris entre 0 et 10, conformément aux règles du jeu
Comme le montre le fragment de code ci-dessous, l’utilisation de séquences pour chaque clé primaire a été mise en œuvre lors de la création de la base de données pour faciliter la saisie des données. Cette automatisation simplifie la procédure globale lors de l’utilisation ultérieure de la boucle Python pour le processus de saisie des données.
CREATE SEQUENCE player_id_seq START 1;CREATE SEQUENCE team_id_seq START 1;CREATE SEQUENCE match_id_seq START 1;CREATE SEQUENCE player_match_id_seq START 1;CREATE SEQUENCE player_rating_id_seq START 1;CREATE SEQUENCE team_match_id_seq START 1;CREATE SEQUENCE team_rating_id_seq START 1;Traitement des données
Le principal défi était de trouver un moyen de traiter les données de match dans une séquence qui permettrait la récupération des IDs des données initiales qui étaient en cours de traitement et insérées dans la base de données.
Ces IDs spécifiques pouvaient ensuite servir de clés étrangères pour gérer les données restantes, créant ainsi les relations nécessaires dans le processus. En d’autres termes, la première étape consistait à identifier et stocker des données spécifiques (IDs) à partir des données brutes, puis à utiliser ces IDs comme pont pour lier et traiter le reste des données.
Les données ont été traitées étape par étape, en utilisant des boucles Python de plus en plus complexes. Chaque nouvelle entrée s’est vue attribuer une clé primaire unique générée à partir de la séquence de la table.
- La première étape consistait à gérer les joueurs individuels et à obtenir leurs IDs.
- Ensuite, les équipes ont été traitées en utilisant les IDs des joueurs. Pour chaque paire unique de joueurs dans un match, une entrée a été créée dans la table ‘Team’ (FK joueurs)
- Ensuite, les matches ont été traités en utilisant les IDs des équipes gagnantes et perdantes. Après le traitement des matches, les tables ‘PlayerMatch’ et ‘TeamMatch’ ont été traitées en récupérant les matchs, les joueurs et les IDs des équipes correspondants
- Une fois toutes les données nécessaires traitées, les IDs des ‘PlayerMatch’ et ‘TeamMatch’, ainsi que les horodatages des ‘matchs’, ont été utilisés dans les tables ‘PlayerRating’ et ‘TeamRating’ pour suivre l’évolution des classements au fil du temps.
Développement d’une application Web
L’objectif de l’application web est de permettre aux utilisateurs de saisir les résultats des matchs, de vérifier les données et d’interagir directement avec la base de données. Cela garantit que les données sont à jour et offertes en temps réel, de sorte que les utilisateurs puissent toujours accéder au classement ou visualiser leurs statistiques.
De plus, je voulais rendre l’application web adaptée aux mobiles, car qui voudrait traîner un ordinateur portable pour jouer au baby-foot ? Ce ne serait pas très pratique ni amusant.
Technologies utilisées
BackendAprès avoir comparé Django et Flask, deux frameworks web populaires pour la construction d’applications web en Python, Flask a été choisi pour son approche adaptée aux débutants. Le framework web Flask est utilisé pour gérer les requêtes des utilisateurs, traiter les données et interagir avec la base de données PostgreSQL.
FrontendLe frontend est composé de fichiers HTML et CSS statiques, qui définissent la structure et le style de l’application web. JavaScript est utilisé pour la validation des formulaires et la gestion des interactions avec les utilisateurs. Cela garantit que les données soumises par les utilisateurs sont cohérentes et précises avant d’être envoyées au backend.
Visualisation des donnéesEn ce qui concerne la visualisation des données, le plus grand défi est d’avoir des données à jour. Pour surmonter cette limitation, la couche de visualisation des données utilise Plotly, une bibliothèque Python, pour générer des graphiques interactifs qui visualisent l’évolution des notes des joueurs au fil du temps. Ce composant reçoit des données du backend, les traite et les présente aux utilisateurs dans un format convivial.
Base de donnéesPostgreSQL a été utilisé à la fois pour l’environnement de développement local et pour l’environnement de production sur AWS, via Heroku. Les sauvegardes automatiques de la base de données sont facilitées par Heroku, garantissant que les données sont protégées et peuvent être facilement restaurées si nécessaire.
Recherche UI/UX
Pour la conception UI/UX, l’inspiration a été puisée dans les designs web modernes de Spotify et du nouveau moteur de recherche Bing. L’objectif était de créer une expérience utilisateur familière et intuitive.
Fonctionnalités de l’application
Plongeons dans les fonctionnalités de l’application avec un scénario concret. L’équipe 1 (Matthieu et Gabriel) souhaite jouer contre l’équipe 2 (Wissam et Malik). Tous les joueurs ont une note différente qui est représentative de leur niveau de compétence, comme indiqué ci-dessous.

Calculer les chances
La première chose que les joueurs veulent faire avant un match est de calculer leur probabilité de victoire.
Pour ce faire, la vue “Calculer les chances” permet aux utilisateurs de sélectionner quatre joueurs à l’aide du menu déroulant et de générer la probabilité de victoire pour les équipes sélectionnées.
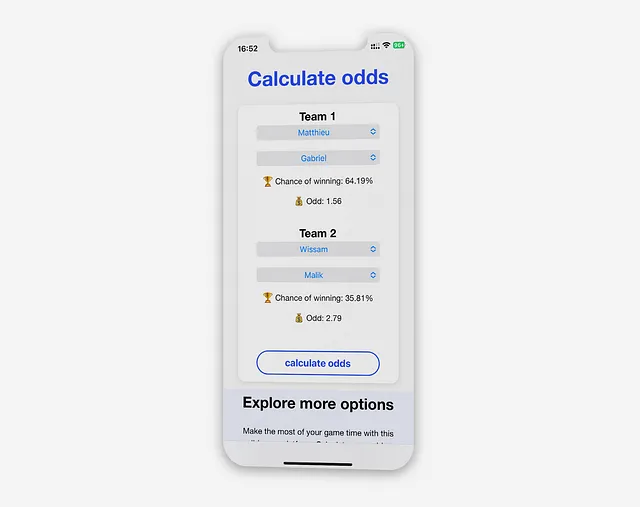
Cette fonctionnalité est principalement utilisée avant un match pour vérifier si celui-ci est équilibré et informer les joueurs de leur probabilité de victoire. Par exemple, l’équipe 1 a une plus grande chance de gagner (64,19%) que l’équipe 2 qui a une probabilité de victoire de 35,81%. Cette vue informe chaque joueur des enjeux et des risques pris.
Une fois le formulaire soumis, l’application calcule uniquement la première partie de l’algorithme, qui consiste à calculer le résultat attendu d’un match en fonction des quatre joueurs sélectionnés.
Télécharger un match
La vue “Télécharger un match” sert de page d’accueil de l’application. Elle est conçue pour la commodité de l’utilisateur, lui permettant de télécharger un match dès l’ouverture de l’application.
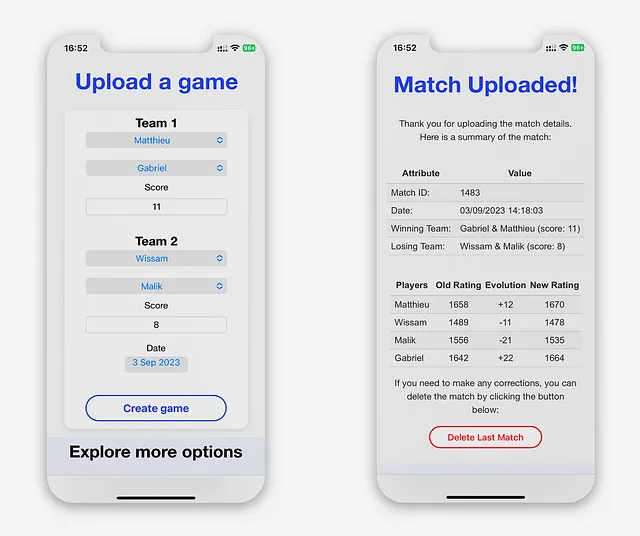
Avant que le formulaire soit soumis, l’application effectue une validation des données à l’aide de JavaScript pour s’assurer que :
- Quatre joueurs différents sont sélectionnés
- Les scores sont des entiers positifs
- Il n’y a qu’une seule équipe gagnante avec un score de 11, sans matchs nuls autorisés
Lorsque la validation est réussie, l’application traite les données à l’aide de l’algorithme complet, met à jour les tables correspondantes dans la base de données et donne aux utilisateurs une confirmation de leur téléchargement.
La vue “Match Uploaded” est conçue pour montrer aux utilisateurs l’effet de chaque match sur leurs notes individuelles. Elle calcule la différence entre les notes des joueurs avant et après le téléchargement du match.
Comme indiqué ci-dessus, le jeu n’a pas le même effet sur la note de chaque joueur. Cela est dû aux paramètres individuels de l’algorithme de chaque joueur : leur score attendu, leur nombre de parties, leur coéquipier et l’équipe adverse.
Classement Elo
La vue “Player Ranking” permet aux utilisateurs d’accéder au classement mensuel en temps réel et de se comparer à d’autres joueurs. Les utilisateurs peuvent voir leur note, le nombre de parties jouées pendant le mois et la dernière partie jouée, montrant leur dernière note.
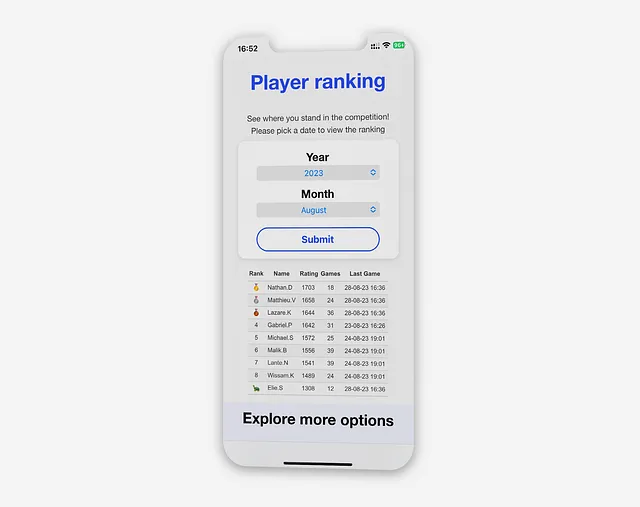
Une fois que la vue “Player Ranking” est consultée ou qu’une nouvelle période est soumise, l’application interroge la base de données en utilisant une approche CTE.
Cela implique de joindre toutes les tables nécessaires et d’afficher la mise à jour de classement la plus récente, en utilisant le sélecteur de période pour filtrer la requête :
def get_latest_player_ratings(month=None, year=None): now = datetime.now() default_month = now.month default_year = now.year selected_year = int(year) if year else default_year selected_month = int(month) if month else default_month start_date = f'{selected_year}-{selected_month:02d}-01 00:00:00' end_date = f'{selected_year}-{selected_month:02d}-{get_last_day_of_month(selected_month, selected_year):02d} 23:59:59' query = ''' AVEC max_player_rating_timestamp AS ( SELECT pm.player_id, MAX(pr.player_rating_timestamp) as max_timestamp FROM PlayerMatch pm JOIN PlayerRating pr ON pm.player_match_id = pr.player_match_id WHERE pr.player_rating_timestamp BETWEEN %s AND %s GROUP BY pm.player_id ), filtered_player_match AS ( SELECT pm.player_id, pm.match_id FROM PlayerMatch pm JOIN max_player_rating_timestamp mprt ON pm.player_id = mprt.player_id ), filtered_matches AS ( SELECT match_id FROM Match WHERE match_timestamp BETWEEN %s AND %s ) SELECT CONCAT(p.first_name, '.', SUBSTRING(p.last_name FROM 1 FOR 1)) as player_name, pr.rating, COUNT(DISTINCT fpm.match_id) as num_matches, pr.player_rating_timestamp FROM Player p JOIN max_player_rating_timestamp mprt ON p.player_id = mprt.player_id JOIN PlayerMatch pm ON p.player_id = pm.player_id JOIN PlayerRating pr ON pm.player_match_id = pr.player_match_id AND pr.player_rating_timestamp = mprt.max_timestamp JOIN filtered_player_match fpm ON p.player_id = fpm.player_id JOIN filtered_matches fm ON fpm.match_id = fm.match_id GROUP BY p.player_id, pr.rating, pr.player_rating_timestamp ORDER BY pr.rating DESC; '''Visualisation des données
L’objectif principal de cette solution complète était de fournir aux utilisateurs un système de classement en temps réel qui sert de représentation visuelle des performances de chaque joueur.
Malgré l’existence d’outils puissants tels que PowerBI et Qlik pour la visualisation des données, une solution entièrement compatible avec les appareils mobiles a été choisie, permettant aux utilisateurs d’obtenir des informations en temps réel sur leurs appareils sans frais de licence.
Deux méthodes ont été utilisées pour y parvenir :
- Tout d’abord, Dash Plotly, un framework Python qui permet aux développeurs de créer des applications interactives basées sur des données au-dessus des applications Flask, a été utilisé
- Ensuite, diverses requêtes SQL et des pages HTML statiques ont été utilisées pour extraire des informations de la base de données et les afficher, garantissant ainsi que les utilisateurs ont toujours accès à des données en temps réel
Évolution du classement
Cette visualisation permet aux joueurs d’observer l’impact de chaque partie sur leur classement et d’identifier des tendances plus générales. Par exemple, ils peuvent voir exactement quand quelqu’un les dépasse ou voir l’impact de victoires ou de défaites consécutives.
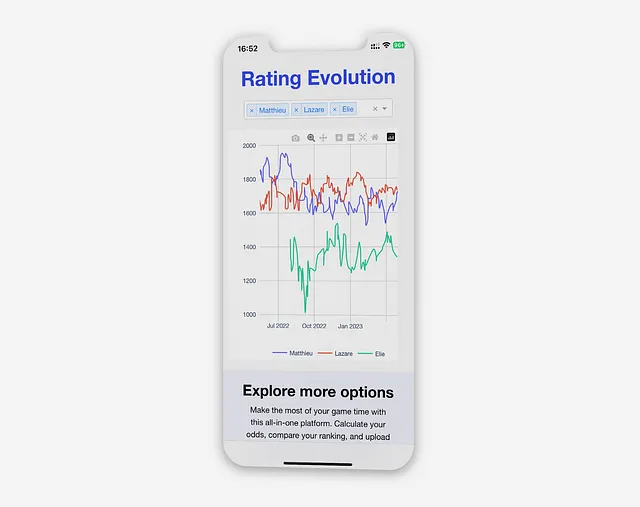
Lors de l’accès à la vue “Évolution du classement”, l’application effectue une requête sur la base de données pour chaque joueur sélectionné, récupérant la mise à jour de classement la plus récente pour chaque jour où un match a été joué :
SELECT DISTINCT ON (DATE_TRUNC('day', m.match_timestamp)) DATE_TRUNC('day', m.match_timestamp) AS day_start, CASE WHEN p.first_name = '{player}' THEN pr.rating ELSE NULL END AS ratingFROM PlayerMatch pmJOIN Player p ON pm.player_id = p.player_idJOIN PlayerRating pr ON pm.player_match_id = pr.player_match_idJOIN Match m ON pm.match_id = m.match_idWHERE p.first_name = '{player}'ORDER BY DATE_TRUNC('day', m.match_timestamp) DESC, m.match_timestamp DESCLe tableau de données récupérées est ensuite transformé en un graphique linéaire, les colonnes étant converties en axes à l’aide de Dash.
Pour réduire la charge de la base de données et simplifier la présentation des données dans le graphique, seule la dernière mise à jour du classement est affichée pour chaque jour.
Métriques du joueur
S’inspirant de Spotify Wrapped, l’idée est de fournir des informations dérivées de la collecte constante de données. Bien qu’il existe un immense potentiel pour visualiser les informations sur les joueurs, l’accent est mis sur les métriques qui mettent en évidence les performances individuelles et les connexions entre les joueurs.
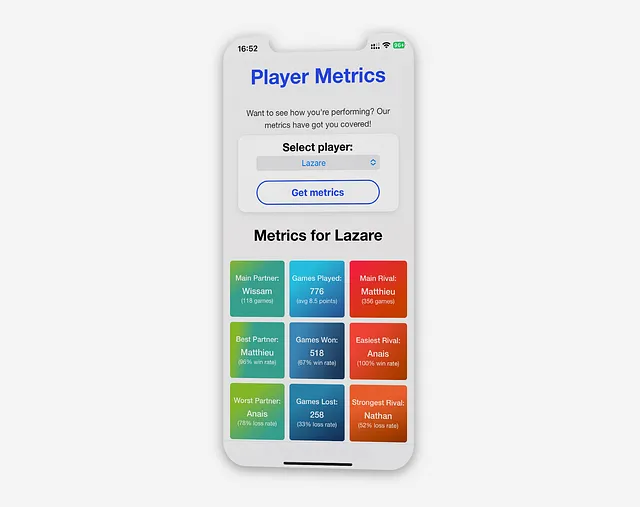
Ces métriques sont organisées en trois catégories codées par couleur : partenaire, jeux et rivaux, chaque métrique étant accompagnée d’un titre, d’une valeur et d’une sous-mesure pour plus de détails.
Métriques de jeuCes métriques sont centrées sur l’écran et affichées en bleu pour la neutralité. Elles incluent le nombre total de parties jouées depuis le début de la collecte des données.
Métriques de partenaireLes métriques de partenaire apparaissent sur le côté gauche de l’écran. Elles sont affichées en vert en raison de leur connotation positive.
- La première case met en évidence le partenaire principal avec lequel le joueur sélectionné a joué le plus de parties
- La deuxième métrique identifie le meilleur partenaire du joueur. Cela est défini par le pourcentage de victoires le plus élevé
- La troisième métrique de cette catégorie est le pire partenaire du joueur sélectionné. Cela est calculé en fonction du pourcentage de victoires le plus bas (ou du pourcentage de défaites le plus élevé)
Métriques de rivalLes métriques de rival sont affichées en rouge pour indiquer l’opposition. Les métriques de rival représentent la relation compétitive entre les joueurs.
- La première case montre l’adversaire le plus fréquent, avec une sous-métrique indiquant le nombre de parties jouées ensemble, similaire aux métriques de partenaire
- La deuxième métrique, “Adversaire le plus facile”, représente l’adversaire contre lequel le joueur a le taux de victoire le plus élevé. Cela indique un adversaire plus faible
- La dernière métrique est le joueur contre lequel le joueur sélectionné a le taux de victoire le plus bas. Cette métrique indique l’adversaire le plus difficile
Conclusion
En écrivant ceci, cela fait 6 mois que l’application est en cours d’utilisation, et voici les résultats obtenus jusqu’à présent :
- Ce système de classement basé sur le système Elo prédit les résultats des matchs et classe précisément les joueurs en fonction de leurs performances réelles
- Les joueurs sont devenus plus compétitifs, car ils sont maintenant de plus en plus conscients de leurs performances grâce à la visualisation des données
- Les joueurs sont devenus plus inclusifs grâce à une formule améliorée qui récompense les joueurs prenant des risques. Les joueurs qui ne joueraient normalement pas ensemble ont maintenant l’incitation à faire équipe
En adoptant une stratégie axée sur les données, ce projet a mis en évidence l’influence profonde et l’importance des données.
Allant au-delà de l’analyse simple des performances des joueurs, ce projet a initié une transformation dans la façon dont les joueurs abordent les parties de baby-foot et interagissent avec d’autres joueurs ainsi qu’avec les nouveaux venus. Le pouvoir des données a réellement favorisé un environnement plus inclusif et compétitif.
Merci d’avoir lu jusqu’ici ! J’espère que vous avez trouvé cet article utile. Si vous souhaitez lire l’intégralité du document, il est disponible ici. De plus, tout le code est disponible sur Github.
N’hésitez pas à partager vos réflexions dans les commentaires 🙂
We will continue to update IPGirl; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Combler le fossé entre les cliniciens et les modèles linguistiques dans le domaine de la santé Découvrez MedAlign, un ensemble de données généré par les cliniciens pour suivre les instructions des dossiers médicaux électroniques.
- Des chercheurs de Microsoft introduisent Hydra-RLHF une solution à mémoire efficace pour l’apprentissage par renforcement avec rétroaction humaine.
- Des chercheurs du MIT proposent AskIt un langage spécifique au domaine pour simplifier l’intégration de modèles de langage importants dans le développement logiciel.
- Comment Ideogram révolutionne la conversion texte-image ? La plateforme d’IA qui va au-delà de DALL-E et Midjourney pour générer des lettres
- Découvrez WavJourney un cadre AI pour la création audio compositionnelle avec de grands modèles de langage
- Apprentissage en ensemble avec Scikit-Learn Une introduction conviviale
- Comment vider sa boîte de réception Gmail avec l’IA ?





