Des chercheurs de l’UC Berkeley et de Meta AI proposent un modèle de reconnaissance d’action lagrangien en fusionnant la pose 3D et l’apparence contextualisée sur les tracklets.
Researchers from UC Berkeley and Meta AI propose a Lagrangian action recognition model by merging 3D pose and contextualized appearance on tracklets.


Il est habituel en mécanique des fluides de distinguer les formulations du champ d’écoulement lagrangien et eulérien. Selon Wikipedia, la “spécification lagrangienne du champ d’écoulement” est une approche pour étudier le mouvement des fluides où l’observateur suit un paquet discret de fluide alors qu’il s’écoule dans l’espace et le temps. La trajectoire d’un paquet peut être déterminée en graphant sa position au fil du temps. Ceci peut être illustré en flottant le long d’une rivière tout en étant assis dans un bateau. La “spécification eulérienne du champ d’écoulement” est une méthode d’analyse du mouvement des fluides qui met l’accent sur les endroits dans l’espace à travers lesquels le fluide s’écoule au fil du temps. En restant assis sur une rive de la rivière et en observant l’eau passer un point fixe, on peut visualiser cela.
Ces idées sont cruciales pour comprendre comment sont examinés les enregistrements d’actions humaines. Selon la perspective eulérienne, ils se concentreraient sur des vecteurs de caractéristiques à certains endroits, tels que (x, y) ou (x, y, z), et considéreraient l’évolution historique tout en restant stationnaires dans l’espace à l’endroit. Selon la perspective lagrangienne, ils suivraient, disons, un être humain dans l’espace-temps et le vecteur de caractéristiques associé. Par exemple, les recherches plus anciennes sur la reconnaissance d’activités employaient fréquemment le point de vue lagrangien. Cependant, avec le développement de réseaux de neurones basés sur la convolution spatio-temporelle 3D, le point de vue eulérien est devenu la norme dans les méthodes de pointe comme les réseaux SlowFast. La perspective eulérienne a été maintenue même après le passage aux systèmes de transformation.
Ceci est important car cela nous offre une chance de réexaminer la question: “Quels devraient être les équivalents des mots dans l’analyse vidéo?” pendant le processus de tokenisation pour les transformateurs. Dosovitskiy et al. ont recommandé des patchs d’image comme une bonne option, et l’extension de ce concept à la vidéo implique que les cuboïdes spatio-temporels pourraient être appropriés pour la vidéo également. Au lieu de cela, ils adoptent la perspective lagrangienne pour examiner le comportement humain dans leur travail. Cela montre clairement qu’ils réfléchissent à la trajectoire d’une entité dans le temps. Dans ce cas, l’entité pourrait être de haut niveau, comme un être humain, ou de bas niveau, comme un pixel ou un patch. Ils choisissent de travailler sur le niveau des “humains-en-tant-qu’entités” car ils s’intéressent à la compréhension du comportement humain.
- S’attaquer à l’écart de généralisation de l’IA des chercheurs de l’University College London proposent Spawrious – une suite de référence pour la classification d’images contenant des corrélations spurious entre les classes et les arrière-plans.
- Révolutionner la synthèse texte-image des chercheurs de l’UC Berkeley utilisent des modèles de langage volumineux dans un processus de génération en deux étapes pour améliorer la compréhension spatiale et le sens commun.
- Des chercheurs de Meta AI et de Samsung ont introduit deux nouvelles méthodes d’IA, Prodigy et Resetting, pour l’adaptation du taux d’apprentissage qui améliorent le taux d’adaptation de la méthode D-Adaptation de pointe.
Pour ce faire, ils utilisent une technique qui analyse le mouvement d’une personne dans une vidéo et l’utilise pour identifier son activité. Ils peuvent récupérer ces trajectoires en utilisant les techniques de suivi 3D récemment publiées PHALP et HMR 2.0. La Figure 1 illustre comment PHALP récupère les trajectoires des personnes à partir de vidéos en les élevant en 3D, ce qui leur permet de relier les personnes à travers plusieurs images et d’accéder à leur représentation 3D. Ils utilisent ces représentations 3D des personnes – leurs postures 3D et leurs emplacements – en tant qu’éléments fondamentaux de chaque jeton. Cela nous permet de construire un système flexible où le modèle, dans ce cas, un transformateur, accepte les jetons appartenant à divers individus avec accès à leur identité, leur posture 3D et leur emplacement 3D en tant qu’entrée. Nous pouvons apprendre sur les interactions interpersonnelles en utilisant les emplacements 3D des personnes dans le scénario.
Leur modèle basé sur la tokenisation surpasse les bases précédentes qui n’avaient accès qu’à des données de posture et peut utiliser le suivi 3D. Bien que l’évolution de la position d’une personne dans le temps soit un signal puissant, certaines activités nécessitent des connaissances de fond supplémentaires sur l’environnement et l’apparence de la personne. Il est donc crucial de combiner la posture avec les données sur l’apparence de la personne et de la scène qui sont dérivées directement des pixels. Pour ce faire, ils utilisent également des modèles de reconnaissance d’actions de pointe pour fournir des données supplémentaires basées sur l’apparence contextualisée des personnes et de l’environnement dans un cadre lagrangien. Ils enregistrent spécifiquement les attributs d’apparence contextualisés localisés autour de chaque trajectoire en exécutant intensivement de tels modèles le long du parcours de chaque trajectoire.
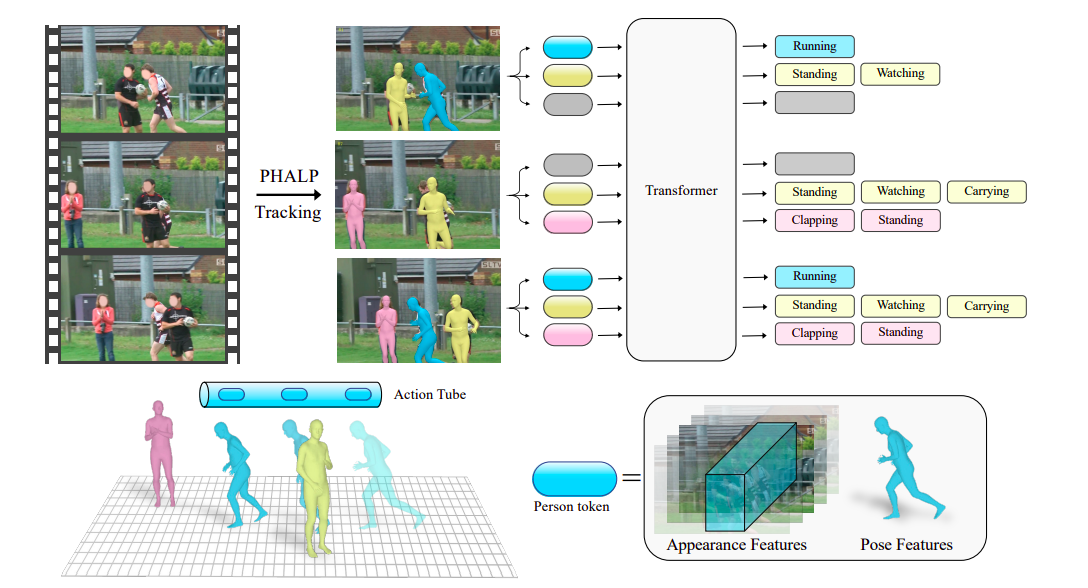
Leurs jetons, qui sont traités par des épine dorsale de reconnaissance d’action, contiennent des informations explicites sur la position en 3D des individus ainsi que des données d’apparence hautement échantillonnées provenant des pixels. Sur le difficile ensemble de données AVA v2.2, leur système dans son ensemble dépasse l’état de l’art précédent de manière significative avec 2,8 mAP. Dans l’ensemble, leur contribution clé est l’introduction d’une méthodologie qui met l’accent sur les avantages du suivi et des poses en 3D pour comprendre le mouvement humain. Des chercheurs de l’UC Berkeley et de Meta AI suggèrent une méthode de reconnaissance d’action lagrangienne avec suivi (LART) qui utilise les pistes des personnes pour prévoir leurs actions. Leur version de base surpasse les versions précédentes qui utilisaient des informations de posture en utilisant des trajectoires sans piste et des représentations de pose en 3D des personnes dans la vidéo. De plus, ils montrent que les lignes de base standard qui ne considèrent que l’apparence et le contexte de la vidéo peuvent être facilement intégrées à la perspective lagrangienne de la détection d’action, ce qui entraîne des améliorations notables par rapport au paradigme dominant.
We will continue to update IPGirl; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Des chercheurs de l’Université de Surrey ont mis au point un outil révolutionnaire de détection d’objets basé sur des croquis en apprentissage automatique.
- Des chercheurs de LinkedIn et de l’UC Berkeley proposent une nouvelle méthode pour détecter les photos de profil générées par l’IA.
- Mon parcours vers l’admission en doctorat en Intelligence Artificielle.
- Les chercheurs de Google présentent AudioPaLM Un bouleversement dans la technologie de la parole – Un nouveau modèle de langage large qui écoute, parle et traduit avec une précision sans précédent.
- Les avancées en informatique aideront les chercheurs à modéliser le climat avec une plus grande précision.
- Robot Chien Fait le Moonwalk à la MJ Cette recherche en IA propose d’utiliser des récompenses représentées dans le code en tant qu’interface flexible entre les LLM et un contrôleur de mouvement basé sur l’optimisation.
- Une nouvelle recherche en intelligence artificielle de l’Université du Maryland, College Park, a développé un système d’IA capable de reconstruire des scènes 3D à partir des réflexions dans l’œil humain.






